Use Data from Amazon S3 in Data Designer
Gainsight NXT
Overview
This article provides guidelines on how Admins can create a dataset in Data Designer by fetching data from a csv/tsv file in any S3 bucket (either Gainsight Managed or Custom buckets).
Business Use Case: If your organization’s IT infrastructure uses Amazon S3 as a data source to store customer success data, and you want to build datasets in Data Designer using that data.
Prerequisites
-
Create an S3 connection in the Connectors 2.0 page to connect the S3 bucket to Gainsight. For more information on this configuration, refer to the Gainsight S3 Connector article.
-
Before a dataset is created in Data Designer, make sure that the source csv/tsv file is available in the required S3 bucket.
Create S3 Dataset
To create an S3 Dataset:
-
From the Data Source dropdown list, select Amazon S3. You can see all of the buckets (Gainsight Managed and Custom buckets) under the selected Amazon S3 source.
-
Gainsight Managed bucket, if you want to fetch a csv/tsv file from the Gainsight Managed bucket. For information on how to ingest data into Gainsight Managed buckets, refer to the Upload CSV/TSV Files into S3 Bucket article.
-
S3 Custom bucket, if you want to fetch a csv/tsv file from your S3 custom bucket.
Note: You can see an S3 bucket here if you have established an S3 connection in the Connectors 2.0 page as shown in the Prerequisites.
- Drag and drop the required Bucket from the list of buckets available on the Canvas screen. You will land on the following page, where you can see Select a File or Folder and its Properties tabs.
Selection of File or Folder
In the File or Folder to Import tab, you can see the list of objects available under the selected S3 bucket. You can select the entire folder or a single file as required.
Select a File
To select an S3 File:
- Click the Object name you wish to import and you will be navigated to the File Selection page.
- Select the required file and click Continue. You will be navigated to the Properties page, where you can select the below mentioned properties.
- Use Date Pattern: Select this to use Date Pattern in the file path. After you select the Use Date Pattern checkbox, you can see the below options:
-
Sample File Name: Displays the Sample File Name.
-
Honor Date Pattern: Select this to Honor the selected date pattern in the File Name.
-
Select or Enter Date Pattern: You can search or select the required date pattern from the dropdown list. You can also type-in the custom date pattern as required.
-
Fetch Data: You can select the number of days to fetch data before the schedule runs.
-
- File Separator: You can use this option if you want to ingest data from multiple files with similar file names into the S3 Dataset. You can use Comma, Pipe, Semicolon, Space or Tab as required.
- Text Qualifier: It is used to import a value (along with special characters) specified in the Quotation while importing data. You can select either Double Quote or Single Quote as required.
- Escape Char: It is used to include a special character in the value and it is placed before a special character in the value. You can select Backslash, Double Quote or Single Quote as required.
- Compression Type: Select the Compression format. You can select None, .bzip or .gzip as required.
- Char Encoding: Select the required Char Encoding. You can select UTF-8, 16, 16BE, ASCII, ISO-8859-1,5589-2,5589-3 as required.
However, Gainsight recommends that you set the file properties as shown below:
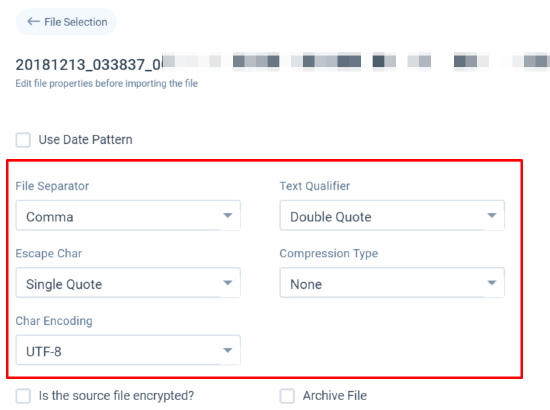
- Is the source file encrypted: Select this if the csv file in the S3 bucket is encrypted. After you select the Is the source file encrypted checkbox, the Available Keys option is enabled and you can select the correct PGP key to apply decryption on the csv/tsv file.
- Archive File: Select the Archive File checkbox to archive the S3 file after use. You must specify a path for the archived folder. A new folder is created in the specified path.
By default, the archived folder is created at the same level at which the source file is located. For example, if your source CSV file is located immediately in the S3 bucket and not nested in any folder, the archived folder is created at the immediate level in the S3 bucket. If your source CSV file is nested in a folder, the archived folder is also created at the nested level. You can modify the default path, if required. - Click Save and Import. You will now be navigated to the Select Fields tab.
Select a Folder
To select a Folder:
- Hover on the Object Name (Folder Name) you wish to import and click Select Folder.
Note: You can Search an Object by its name. In the Search by object name textbox, type in the Object name you want to search for. The Search operation works with the objects available in the S3 bucket. - Click Continue and you will be navigated to the Properties page, where you can select the properties.
- Click Save and Import. You will be navigated to the Select Fields tab.
Select Fields
After you Save and Import the files, you will be navigated to the Select Fields tab. Here, you can see all of the fields from the S3 files available in the selected folder.
To select Fields:
- Select the required fields you want to add to the dataset and click Select.
- You can now Edit Dataset, Add/Delete Fields and set File Properties. For more information, refer to the Edit Dataset section.
- Click Save.
Edit Dataset
To edit a Dataset:
Click the Pencil icon (or) click Options, and then click Edit to edit a dataset. You will land on the following page, where you can see Fields and File Properties tabs.
Fields
You can see the following options in the Fields tab:
- Enter Dataset Name: In the Enter Dataset Name textbox, type In the Dataset Name, if you want to edit the Dataset Name.
- Search Fields: In the Search Fields textbox, type in the Field Name you want to search for. The Search operation works with the fields available in the Dataset.
- Add Fields: Click Add Fields to select the required fields you want to add to the dataset, and then click Select. You can also remove fields from the dataset by deselecting them.
-
+Add Custom Field: If you want to create new fields in the dataset that are not available in the S3 file, click +Add Custom Field. To create new fields:
- Enter the Field Name.
- Select the Data Type.
- Enter the Display Name.
- Click Save. A Warning dialog appears.
- Click Yes Save to save the new field.
- Data Type: You can select and change the Field Data Type.
- Display Name: By default, Field Name name appears in the Display Name textbox; if required you can modify it. Display Names are shown in the Datasets/reports.
- Settings: This option is available only for Date, Number and DateTime data types only. Click the Settings icon to enter/set the decimal places, date and time format.
- For the Date data type fields, you can set the Date Format.
- For the Number data type fields, you can set the Decimal Places.
- For the DateTime data type fields, you can set Date Time Format and Time Zone.
- Delete: Click the Delete icon to delete a field from the dataset.
- Save: Click Save to save the changes made in the dataset.
File Properties
You can see the following options in the File Properties tab:
- Date Pattern: Select this to use Date Pattern in the file path. For more information, refer to the Select a File Step 2a.
- Default Date Format: You can set the Default Date Format by searching or selecting the required pattern from the Date Format, Date Time Format and Time Zone dropdown lists respectively.
- Additional Encryption Properties: For detailed information on Encryption Properties, refer to the Select a File Steps 2b to 2h.
You can also create more Datasets from Salesforce, MDA data and Amazon S3 and perform Merge, Transform and other actions on the created Datasets. Then, you can proceed to the Explore tab to analyze the data and create reports.
Additional Resources
- For information on how to edit, merge or transform the datasets, refer Preparation Details in Data Designer.
- For information on how to explore a dataset, refer Explore Details in Data Designer.
- For information on how to create a dataset, refer Create Datasets in Data Designer.
- For information on the most frequently asked questions on Data Designer, refer Data Designer FAQs.