Gainsight Bulk API
Gainsight NXT
| IMPORTANT: Gainsight is upgrading Connectors 2.0 with Horizon Experience. This article applies to tenants which have been upgraded to the Horizon Experience for Connectors 2.0. If you are using Connectors 2.0 with the previous version, you can find the documentation here. |
This article explains Gainsight admins through the process of creating a connection in the Gainsight Bulk API and configure a data job to generate a cURL command. This command is used to load data into the target Gainsight object from the source CSV file, as configured in the data job.
Note: Data cannot be loaded into the Gainsight User and Person object model using Gainsight Bulk API.
A walkthrough of this article helps Admins to:
- Create a Bulk API connection.
- Create a Job.
- Ingest data into the Gainsight objects from a CSV file.
Overview
Gainsight Bulk API is a channel that loads data into Gainsight using the cURL commands. Customers may want to load data from an external system into Gainsight through a CSV file downloaded from the external system into the local machine. Gainsight Admins can set up the required configurations in the Gainsight Bulk API and share the output cURL command with the developer, who can integrate the command with any application. As configured, the data is loaded directly into Gainsight from the local machine, with an action in the application to which the cURL command is integrated with.
Following are the benefits of using the Gainsight Bulk API:
- Job creation and maintenance is easy.
- Data import into standard objects is available.
- Field Mapping available in the UI.
- Ability to set up Data import Lookup with multiple field mapping.
- Update Keys functionality for Update/Upsert operations.
- Notification emails for Success and Failure of data import.
- Track in detail Execution and Update Activities.
Create a Bulk API Connection
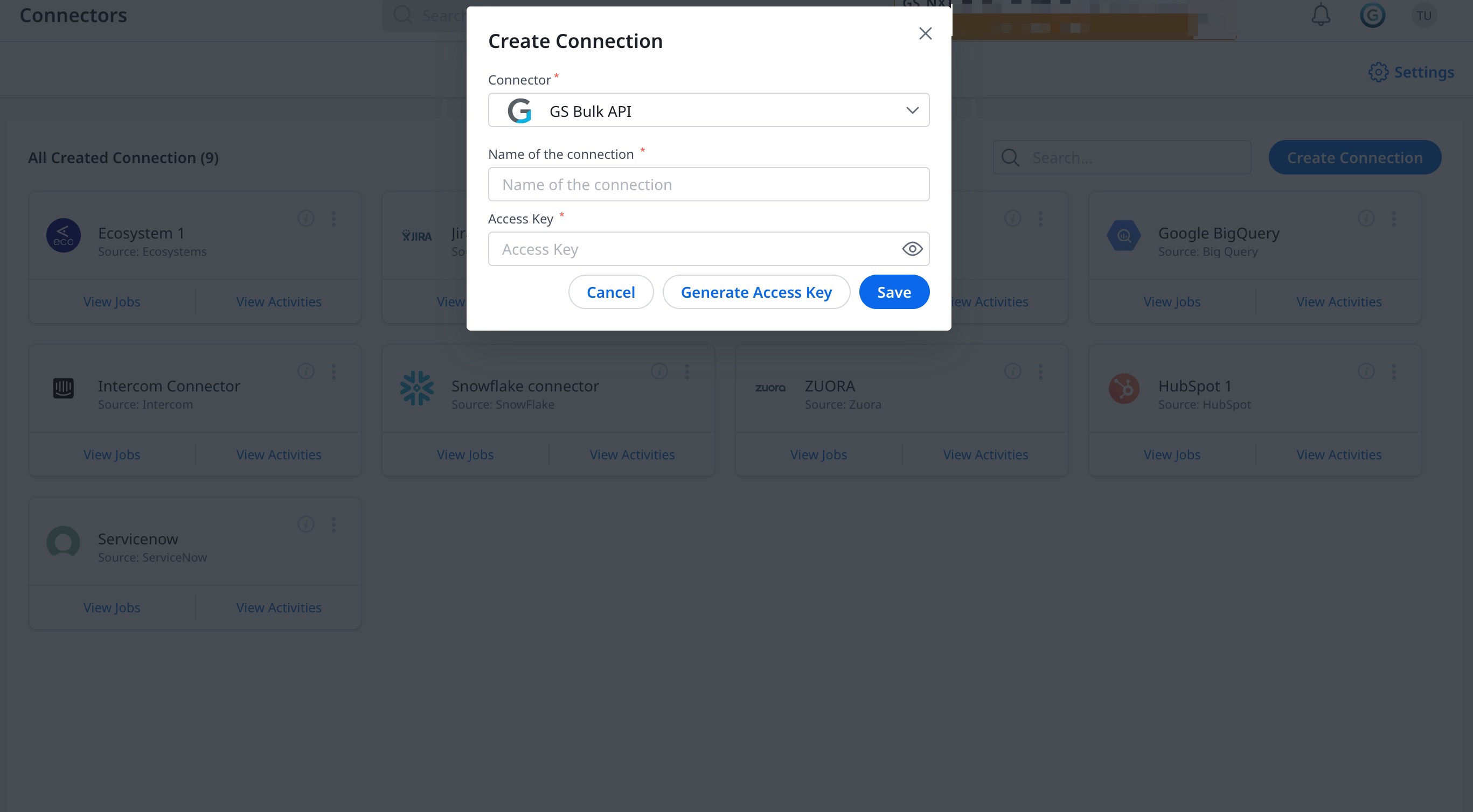
To create a Connection:
- Navigate to Administration > Connectors 2.0 > Connections.
- Click Create Connection. The Create Connection dialog appears.
- From the Connector dropdown list, select GS Bulk API.
- Name of Connection: Enter the name of the connection.
- Click Generate Access Key. A new access key is generated. If you want to reset the access key at any time, click the Generate Access Key.
- Copy the access key and save it to use in the cUrl API section.
Note: Admins can save this Access Key and share with their developers or respective team mates, who can use the cURL command to integrate with an application.
- Click Save.
IMPORTANT: The system allows users to create one connection per org. Under one connection, admins can create multiple Jobs to ingest data into objects.
Limitations: The limits to the Bulk API jobs executions, as follows:
- Bulk API limit per hour for a connection: 10
- Bulk API limit per day for a connection: 100
- The general max file size limit is 80 MB.
Create a Job
Once the connection is established, you can create as many Jobs as you need. To create a Job:
- Navigate to the Jobs page.
- Click Create Job. the Create Job dialog appears.
- In the Name of the Job textbox, enter the Job Name.
- Click Next. The Job Preparation page appears.
- From the Data Source dropdown list, select the required GS Bulk API connection.
The following sections will be loaded on the Preparation page:
- Jobs Details
- Field Mappings
- cURL API
Job Details
The Job Details section displays the following information:
- Connection: Displays the name of the connection.
- Connector: Displays the connector name.
- Job Name: Enter a unique Job name.
- Notification recipients: In the Notification recipients, populate following information:
- Success Recipients: If a job has partial/full data import success, a success notification email is sent to the email address entered here.
- Failure Recipients: When all records fail to import, a failure notification email is sent to the email address entered here.
Note: Multiple emails can be added into the recipient list separated by commas.
- Click Save.
Note: System will validate for any job with the same name. If it finds a duplicate job name, it shows an error Job name already exists. Always assign a unique job name.
Ingest Data into Gainsight Objects from a CSV file
To complete the job creation process, mapping between the CSV columns and the Gainsight object fields is necessary. In this example, records are ingested from the CSV file CompanyDetails.csv into the Company object.
Records in the CSV file with the headers Name, Industry, Employees, Original Contract Date, Renewal Date, ARR, CSMFirstName and CSMLastName are shown below as an example:
Note: The names, records, and Access Key used in this document are just for reference only.

Notes:
- Ensure that the CSV file name does not contain any spaces.
- CSM First Name and Last Name are added here to use them in Derived Mappings.
Make sure that the formats of the Date and DateTime values in the CSV file are supported in Gainsight. For the list of supported formats in Gainsight, refer to the Basic Operations in Data Management in the Additional Resource section at the end of this article.
Admins can create multiple jobs to ingest data into the objects.
Field Mapping
Click the Field Mapping to expand the section and enter the following details:
- Target Object: From the dropdown list of Target Object, select the target object into which you want to ingest data. For example, select Company Object. Once a job is saved with a specific Target Object, it cannot be changed before ingesting data.
- Click BROWSE to select a CSV file from the local machine. The CSV file in this section is uploaded to select mapping between CSV headers and Gainsight object fields.
Notes:- Make sure that the CSV file has headers.
- CSV files having a maximum size of 1MB can be loaded.
- Data Load Operation: Select the required Data Load Operation. Either select Upsert, Update, or Insert for the respective operation.
- For Upsert and Update, click the + icon to set key fields that can be used as identifiers.
- CSV Properties: Select appropriate CSV Properties. Recommended CSV properties:
- Character Encoding: UTF-8.
- Separator: , (Comma)
- Quote Char: “ (Double Quote)
- Escape Char: Backslash
- Header Line: 1 (Mandatory)
- Multi-select separator: ; (Semicolon)
Notes:- Gainsight Bulk API always supports the files which are encoding with UTF-8 only.
- A separator is used to separate the values of different fields in a CSV. User should use the same separator in the job configuration which is used in the CSV file to upload. By default, (comma) is selected as separator but users can change it as required.
- Quote Character is used to import a value (along with special characters) specified in the Quotation while importing data. It is recommended to use the same Quote Character in the job configuration which is used in the CSV file to upload. By default, Double Quote is selected in the job configuration but users can change to Single Quote as required.
- Escape character is used to include a special character in the value. By default, Backslash is used as Escape Character before a special character in the value. It is recommended to use Backslash in the CSV file to avoid any discrepancies in the data after loading.
- A Multi-select separator is used to separate the multiple values of a field of data type multi-select dropdown list. Users should use the same Multi-select separator in the job configuration which is used in the CSV file to upload. By default ; (Semicolon) is selected as separator but users can change it as required.
- Click Fetch Mappings. A success message showing Fields Fetched Successfully appears.
Mappings and Lookup Mappings tabs are displayed.
Mappings
In the Mappings tab:
- Map the Target Fields appropriately to the Source Fields (Headers from the CSV file).
- Select the Data Types for the Source Field. Correspondingly match the Target Object with the appropriate Data Types. The table below shows the source data types with the corresponding possible target data types:
| Source Data Type | Target Data Type |
|---|---|
| String | String, Dropdown list, Email, GSID, Rich Text Area, Multiselect Dropdown List |
| Number | Number, Percentage, Currency |
| Boolean | Boolean |
| Date | Date |
| DateTime | Date Time |
Example: If you select a Number type field in the source, it will show the fields in the target object with Number, Percentage, and Currency data types. You can select the field in the target object as required.
Complex data types (Example: Multiselect dropdown list) in the target object can be mapped from their base data types (Ex: String) in the source CSV fields as shown in the table.
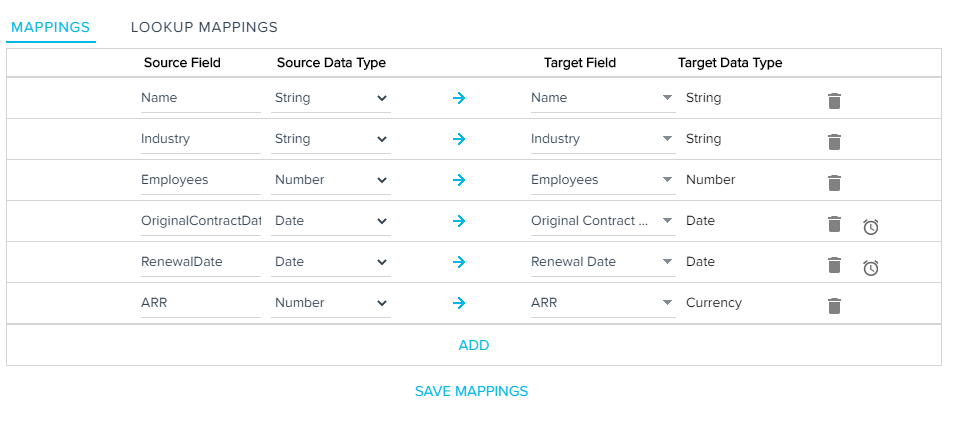
- Click the Clock icon to set Timezone for the Date and DateTime fields. Select a Timezone window appears.
- From the Time Zone dropdown list, select the appropriate Timezone.
- Click Ok.
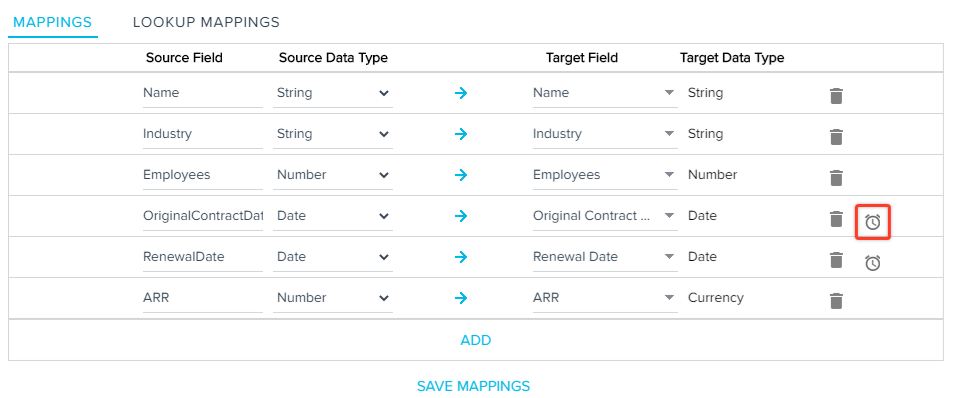
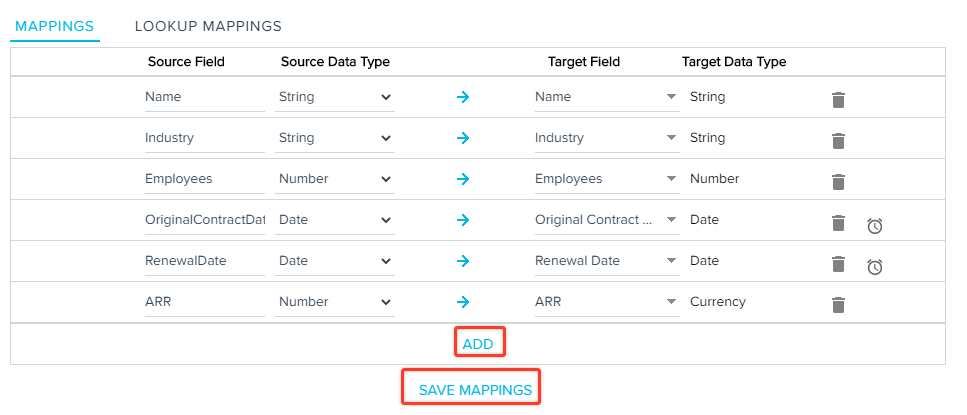
Note: The Date and DateTime values are then converted into UTC from the selected timezone and are stored in the Gainsight object. If you do not select a timezone, the records are considered to be in the Gainsight Timezone. - (Optional) Click ADD to map additional target fields with the CSV source fields.
- Click the Trash icon to delete the Fields, as required.
- Click Save Mappings. A success message showing Matching saved successfully appears.
Lookup Mappings
In the Lookup Mapping section, click ADD. The Data Import Lookup Configuration dialog appears.
This is to lookup to the same or another Gainsight standard object and match fields to fetch Gainsight IDs (GSIDs) from the looked up object and populate in the target field. Derived mappings can be performed only for target fields of GSID data type.
There are 2 types of Lookups:
- Direct Lookup: Direct lookup enables admins to lookup to another Gainsight standard object and fetches GSIDs of the records from the lookup object.
- Self Lookup: Self lookup enables admins to lookup to the same standard object and fetches GSID of another record to the target field.
For more information, refer to the Data Import Lookup in the Additional Resource section at the end of this article.
Perform the following actions in the Data import lookup configuration dialog:
- Lookup Type: From the dropdown list, select Direct or Self lookup, as required.
- From: From the dropdown list, select the Source object.
- To Target Field: From the dropdown list, select corresponding Fields.
- Match By: Match multiple fields between the source CSV file and looked up object to import correct GSID from the standard object into the target object.
- When you have multiple matches or when no match is found, you can select one from the given options, as needed.
- Click Apply.
- Click Save Mappings.
cURL API
To generate the cURL command:
- Navigate to the cURL API section. The cURL Command textbox is displayed.
- Click Generate. cURL Command is generated.
Note: Sub-domain generated in the cURL command is different from the sub-domain of the current org. You can run the command as generated without changing the sub-domain. Tenant is identified uniquely with the entered access key.
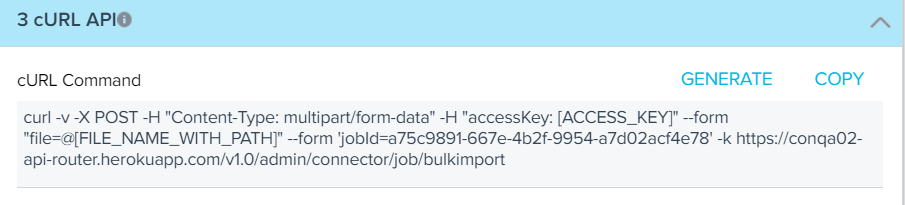
- Click Copy to copy the cURL Command. Paste the cURL command into any text editor.
- In the text editor, enter the Access Key generated in the Create a Bulk API Connection.
- Enter the File Path of the CSV File as shown in the image below.

- Enter the cURL command in the Terminal or Command Prompt and submit. The data is ingested into the target object successfully.
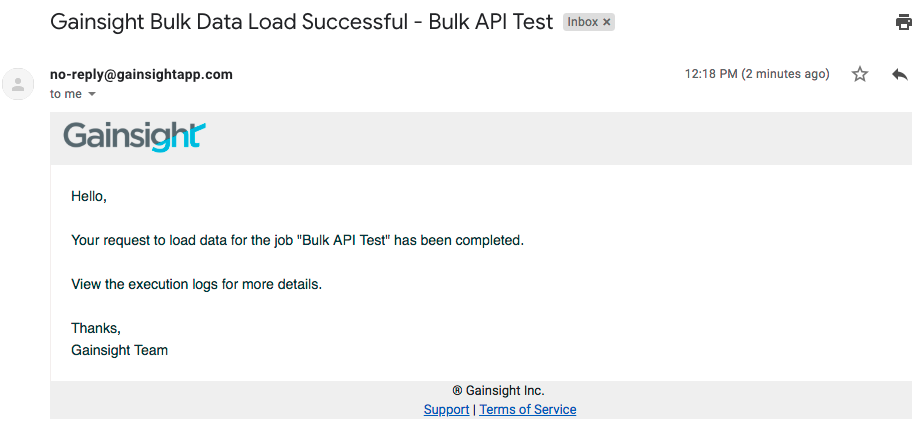
- An email is sent to the recipient to inform the success or failure of the job as shown in image below.
Bulk Status API
The Bulk Status API can be used to check the progress of the Bulk API job. When you successfully run the cURL command, it returns true with the Request ID and Status ID. This Status ID is used to retrieve the data from the Bulk Status API to track the progress of the upload. For more information on the Bulk Status API, refer to the Bulk Status API article.
Job Activities
You can view the Execution and Update Activities of all the data jobs in the Activity page. You can also download the error logs of the jobs from this page to help troubleshoot configuration issues. For more information, refer to the Activity Page in the Additional Resource section at the end of this article.
Additional Resources
For more information about Connectors, refer to: