File Analyzer Admin Guide
Gainsight NXT
Overview
Admins can use the File Analyzer to scan any CSV/TSV file to identify the root cause of any upload issues the file might have. After uploading a file to Gainsight, you can use this feature to assess any records that might have failed the upload. You can also use this feature to proactively identify these issues and resolve them before ingesting the data into Gainsight.
To access the File Analyzer, navigate to Administration > Analyzer > File Analyzer
The File Analyzer has the following subtabs:
- Scan (Beta): Here you can upload CSV/TSV files to scan them.
- Scan History: Displays a list of each scan completed by the File Analyzer.
Limitations:
- Only CSV/TSV file formats are supported.
- The File Analyzer supports uploaded files that are less than 10 MB and S3 files that are less than 100 MB.
- Uploaded files should contain headers.
- Compressed and Encrypted files are not supported.
- Files uploaded to the analyzer, and any generated error files will be stored in your S3 bucket for 30 days and will be deleted after this time.
Scan (Beta)
Under the Scan tab, admins can upload CSV/TSV files to scan them for potential upload issues. Take the following steps to complete a file scan:
- Select the type of data you want to analyze. The dataset you select will determine how File Analyzer validates the data. For the purposes of this tutorial, we’ll be selecting the Company dataset. You can select the following types of datasets for analysis
- User: When you select this dataset option, the File Analyzer will validate the data you upload against the Gainsight Standard User object.
- Company: When you select this dataset option, the File Analyzer will validate the data you upload against the Gainsight Standard Company object.
- People: When you select this dataset option, the File Analyzer will validate the data you upload against the Gainsight Standard Person object
- Relationship: When you select this dataset option, the File Analyzer will validate the data you upload against the Gainsight Standard Relationship object.
- Custom Object: When you select this dataset option, the File Analyzer will validate the data you upload against an existing MDA custom object that you select.
- Generic File: When you select this dataset option, the File Analyzer will validate the data you upload irrespective of data type.
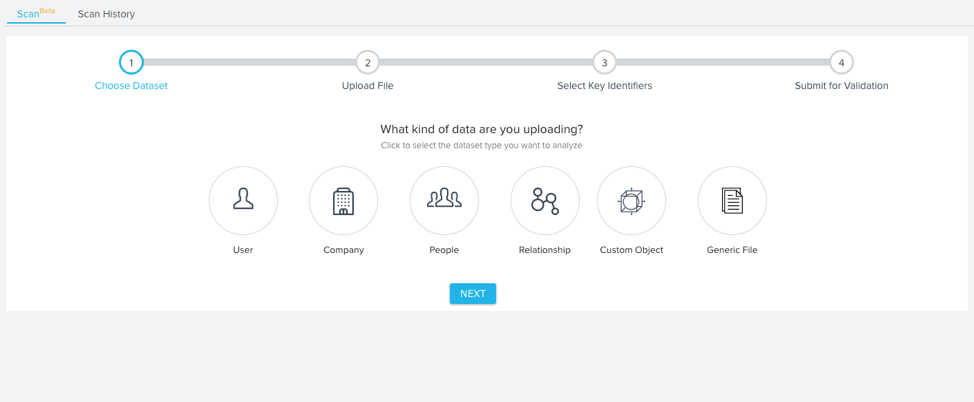
- Click Next.
- Upload your file for analysis either directly from your local machine, or from an S3 Bucket. Use the following tools to configure your file upload method:

- Click SELECT to upload a file directly from your local machine.
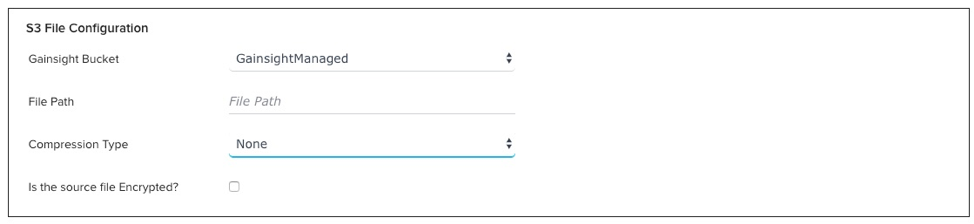
- Click SELECT to read a file from an S3 Bucket. Selecting this option displays the S3 File Configuration section which you must fill out before proceeding. For more information on S3 File Configuration, refer to Gainsight S3 Connector under Additional Resources.
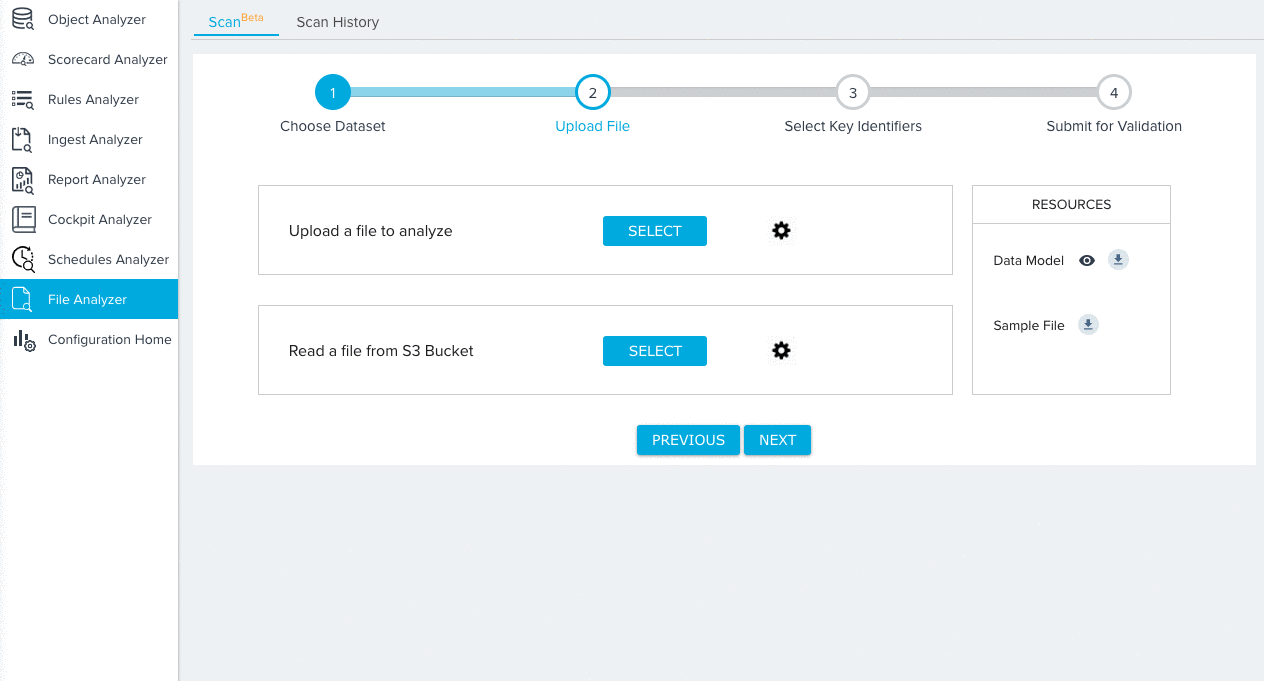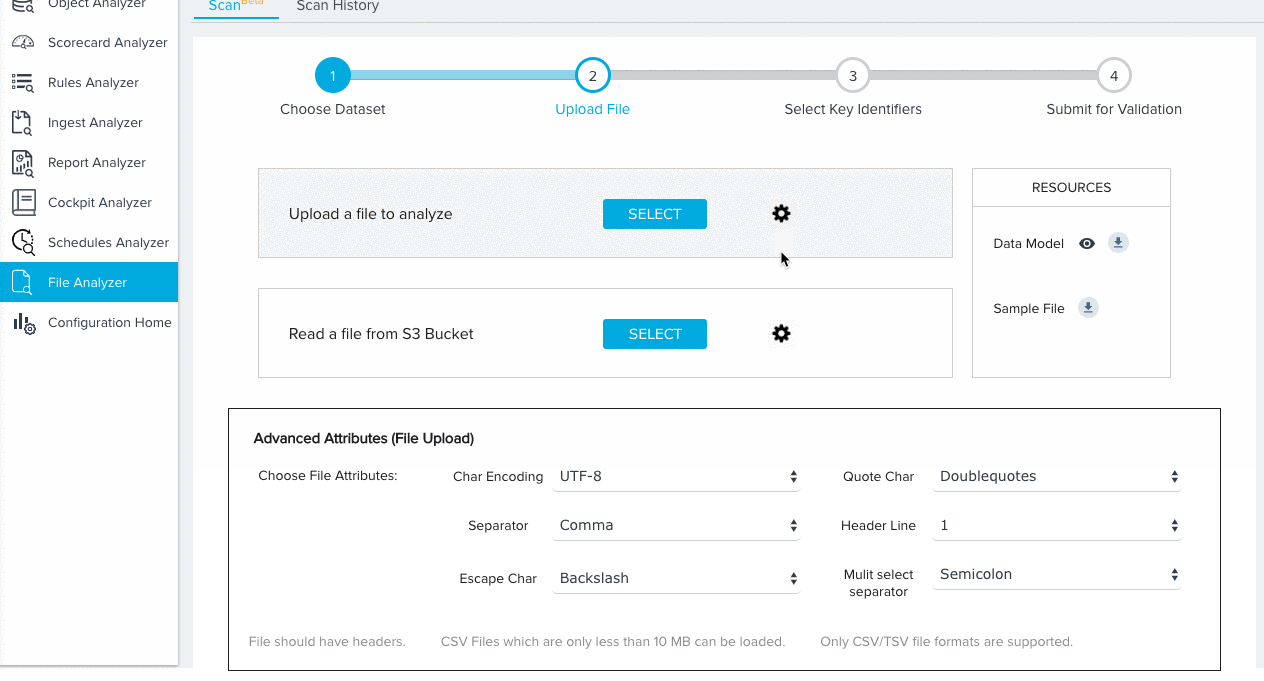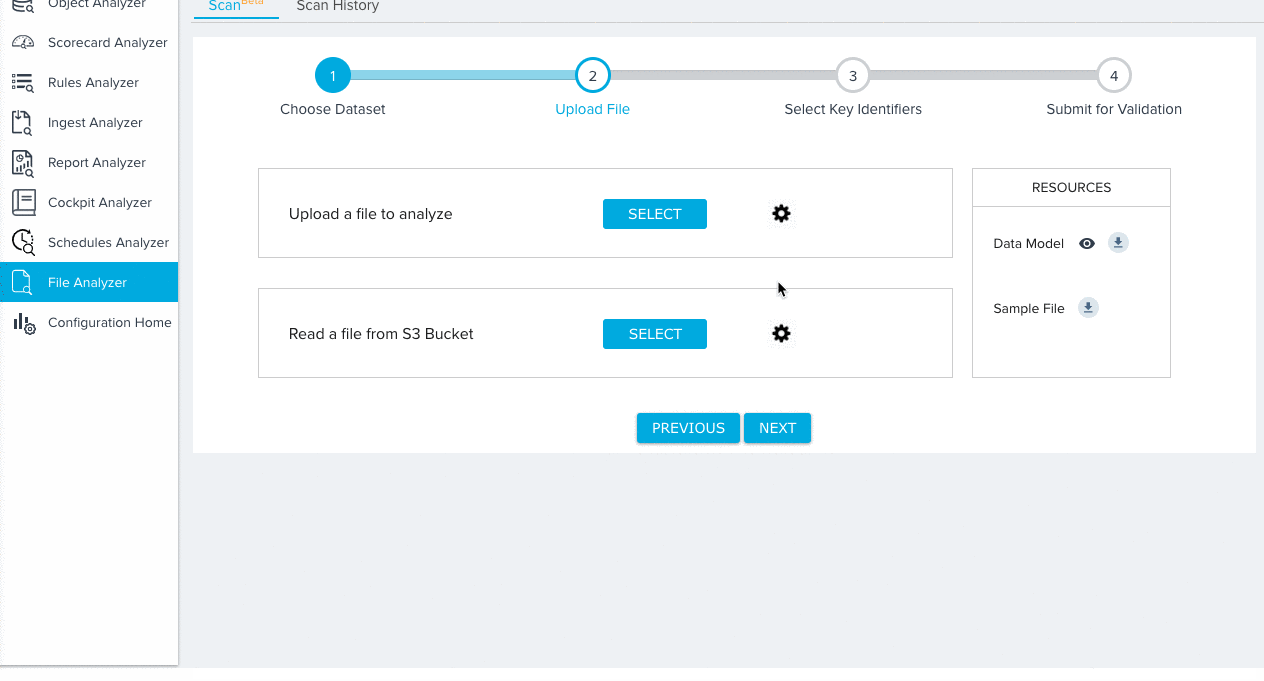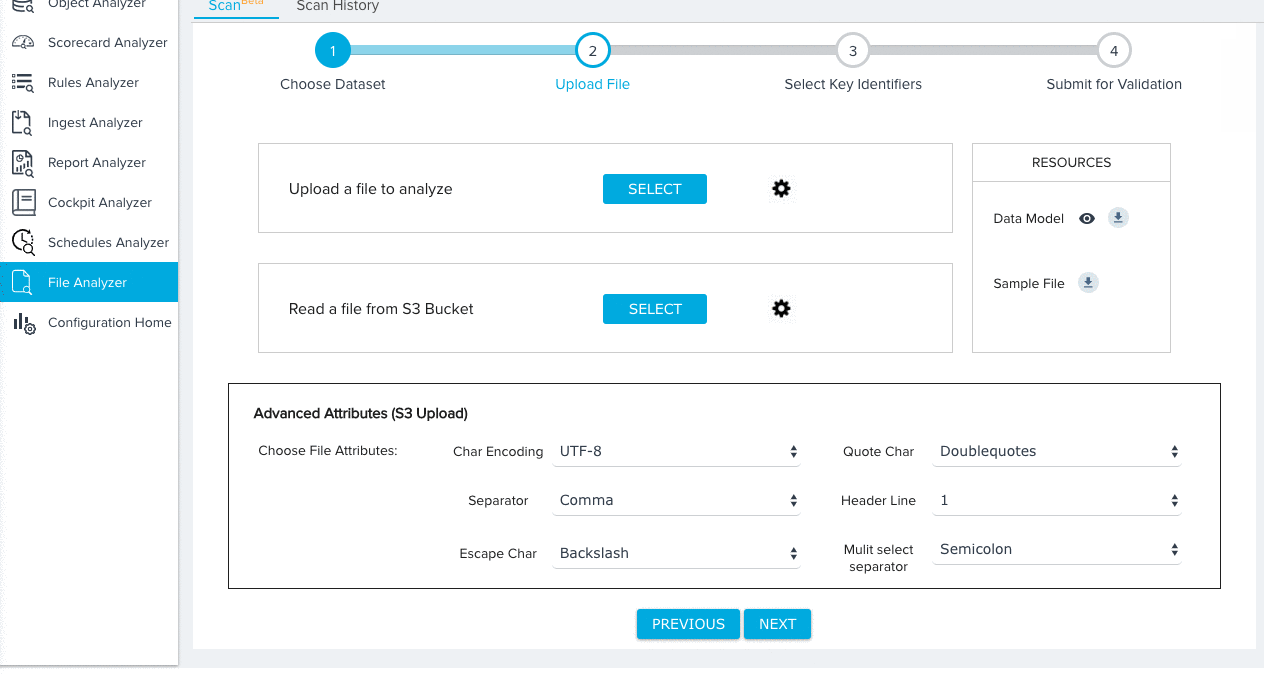
- Click to configure the following Advanced Attributes for either upload option:
- Character Encoding
- Separator
- Escape Character
- Quote Character
- Header Line
- Multi select separator
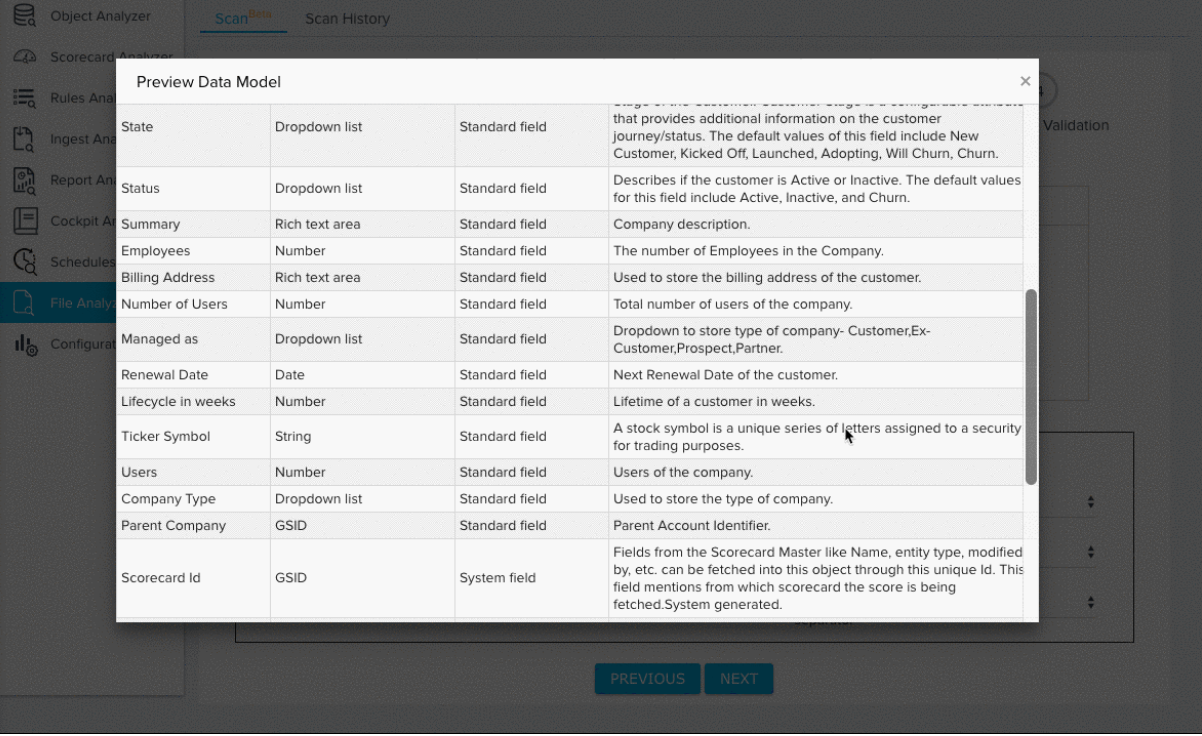
- Click the Eye icon to preview the Data Model you selected. Click the Download icon to download the preview as a CSV.
Note: This option is not available for the Custom Object and Generic File datasets.
- Click the Download icon to download a sample file for the selected Data Model as a CSV.
Note: This option is not available for the Custom Object and Generic File datasets.
- Click Next
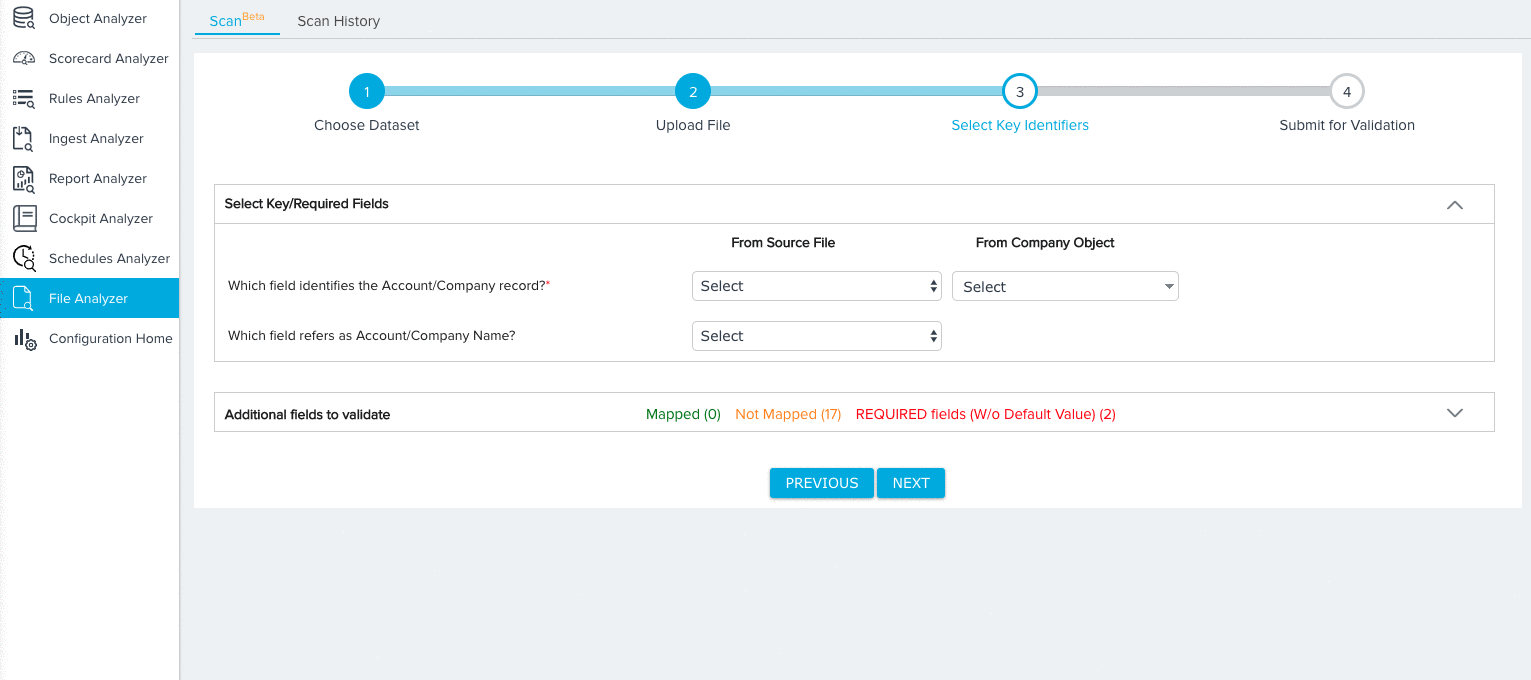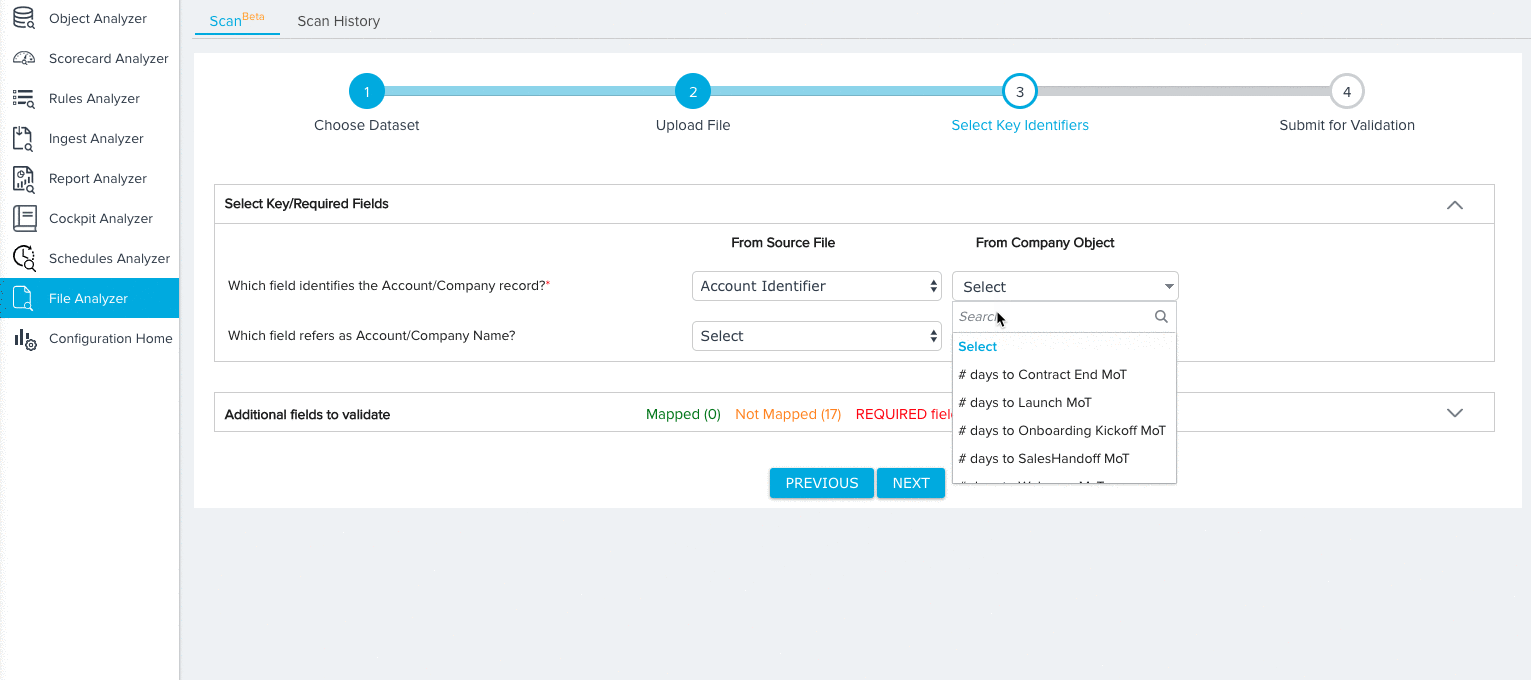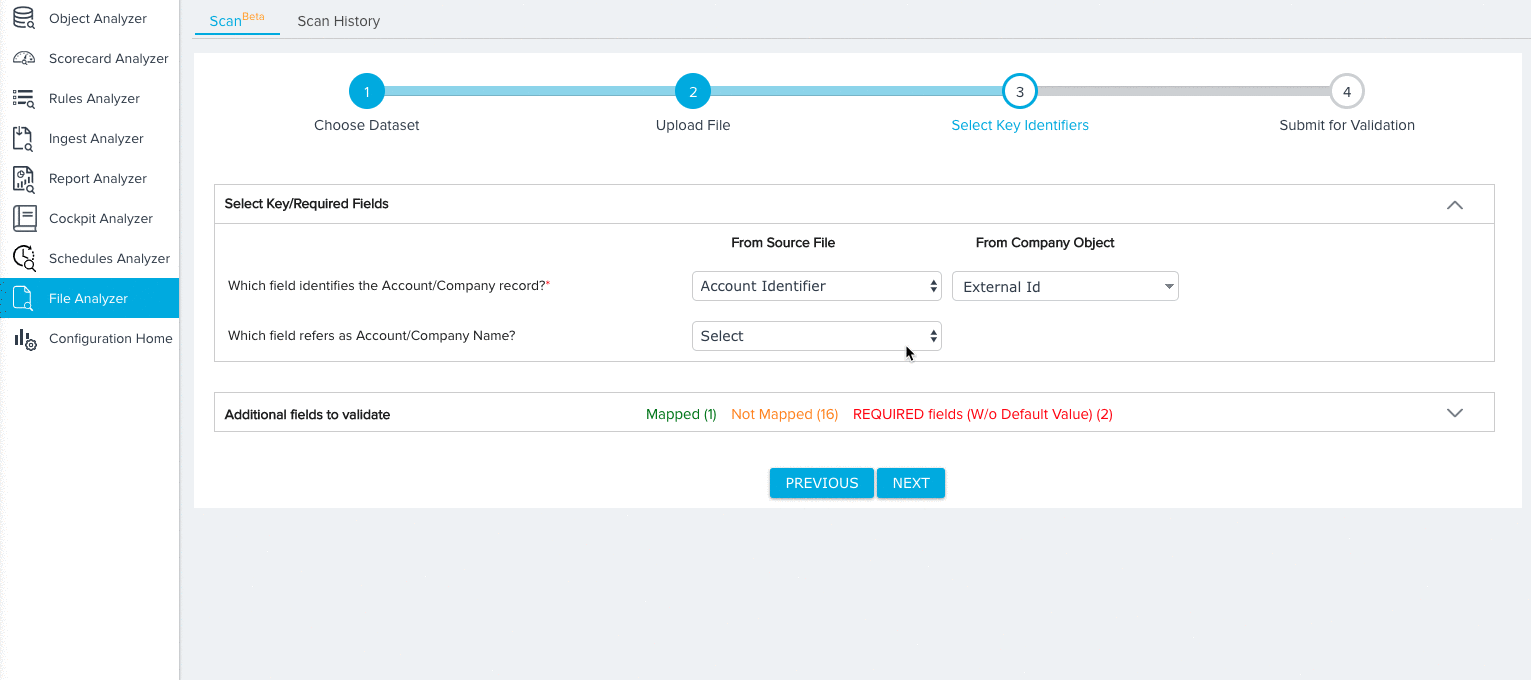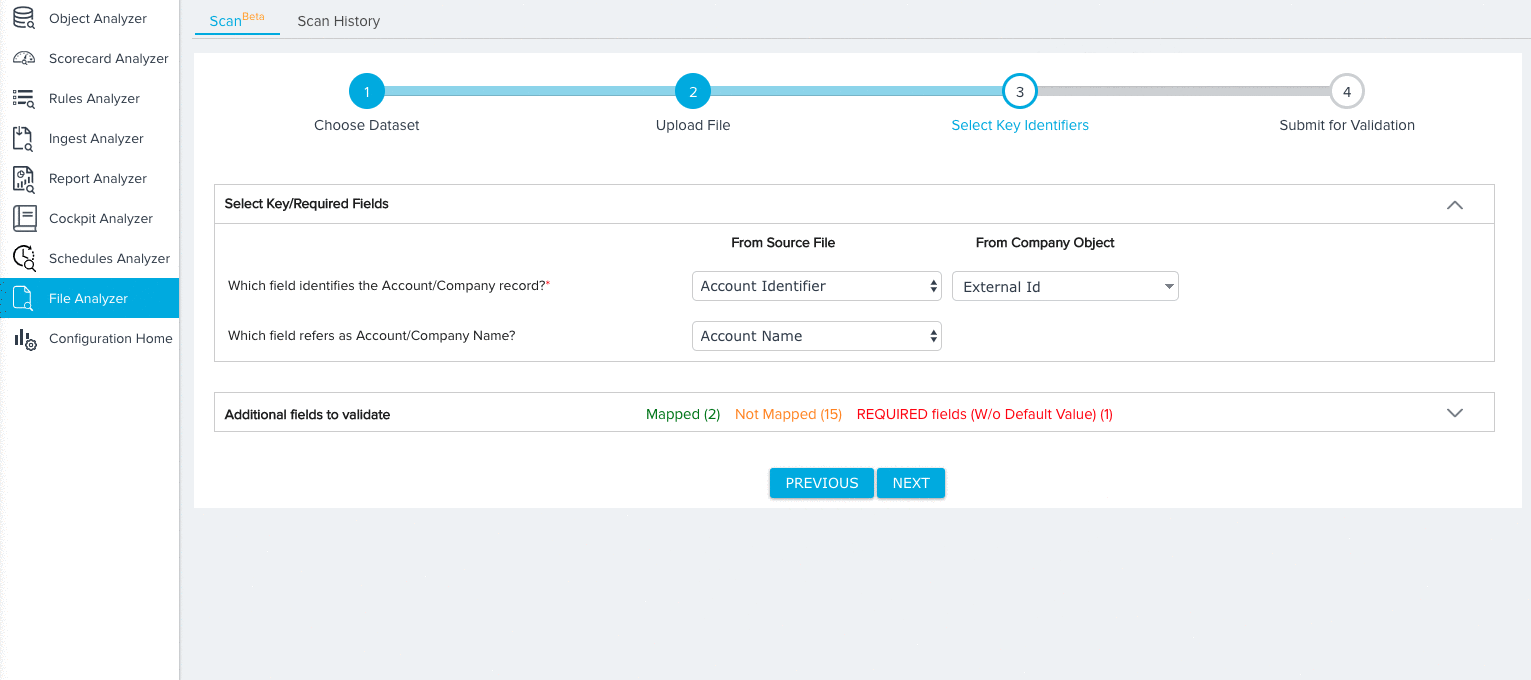
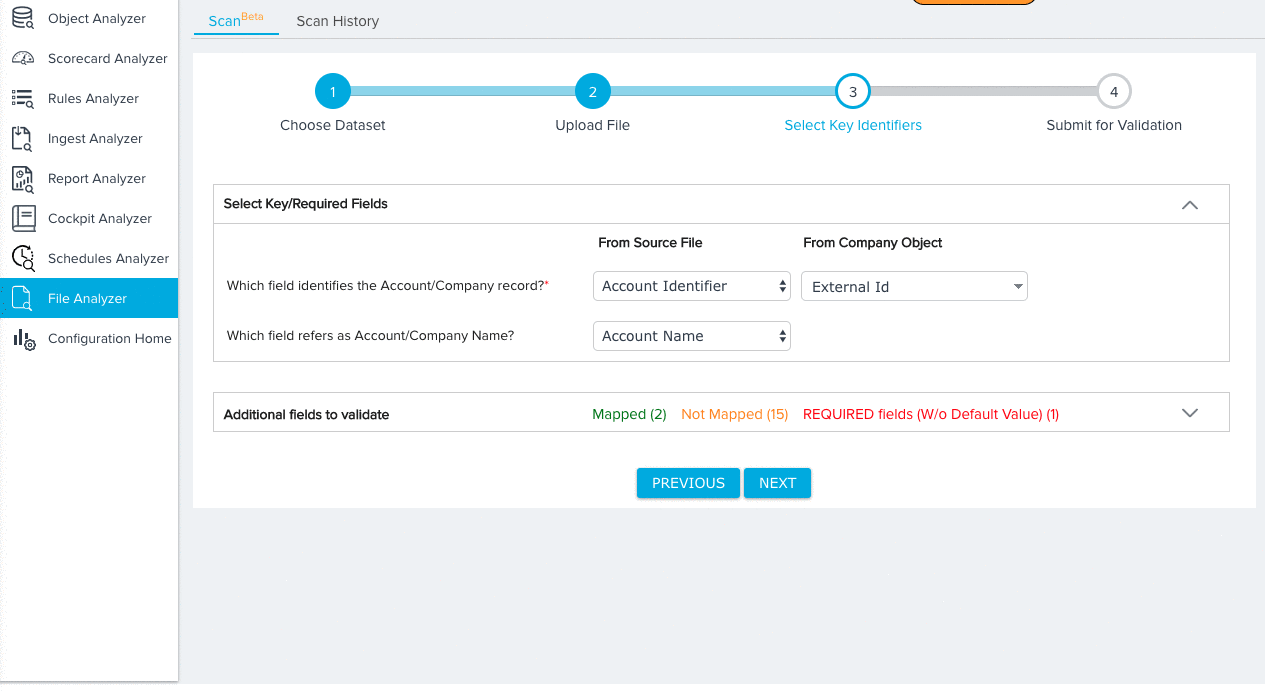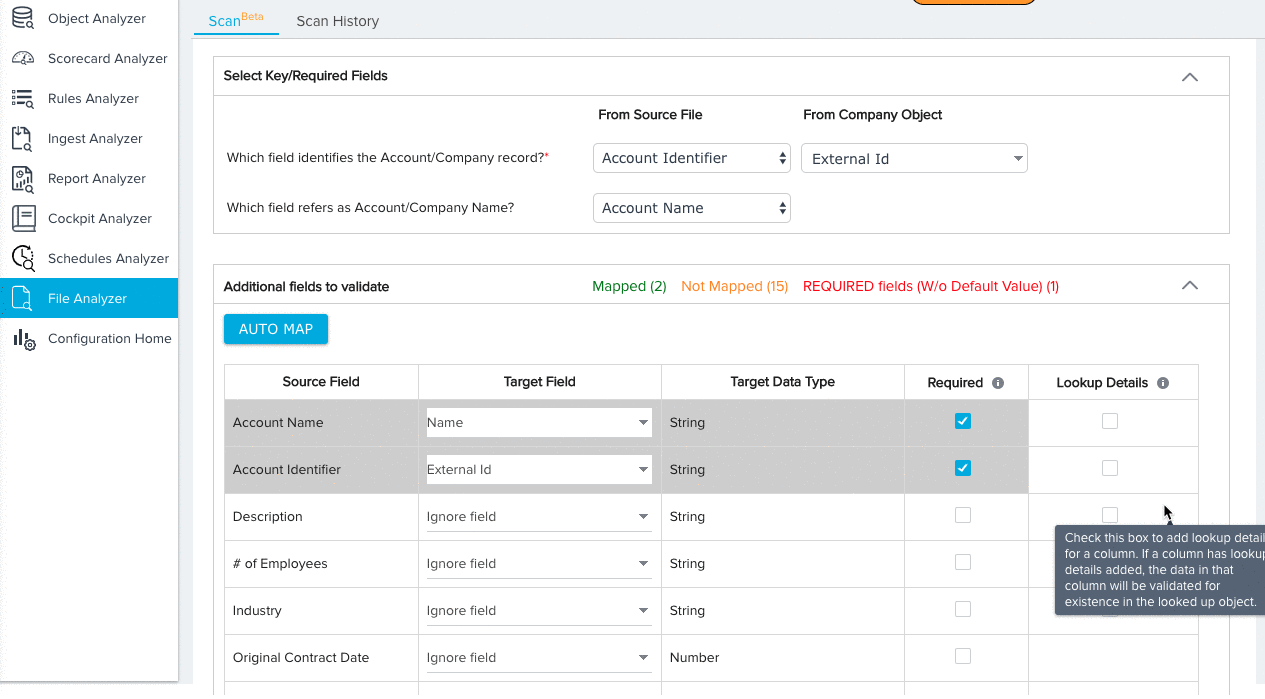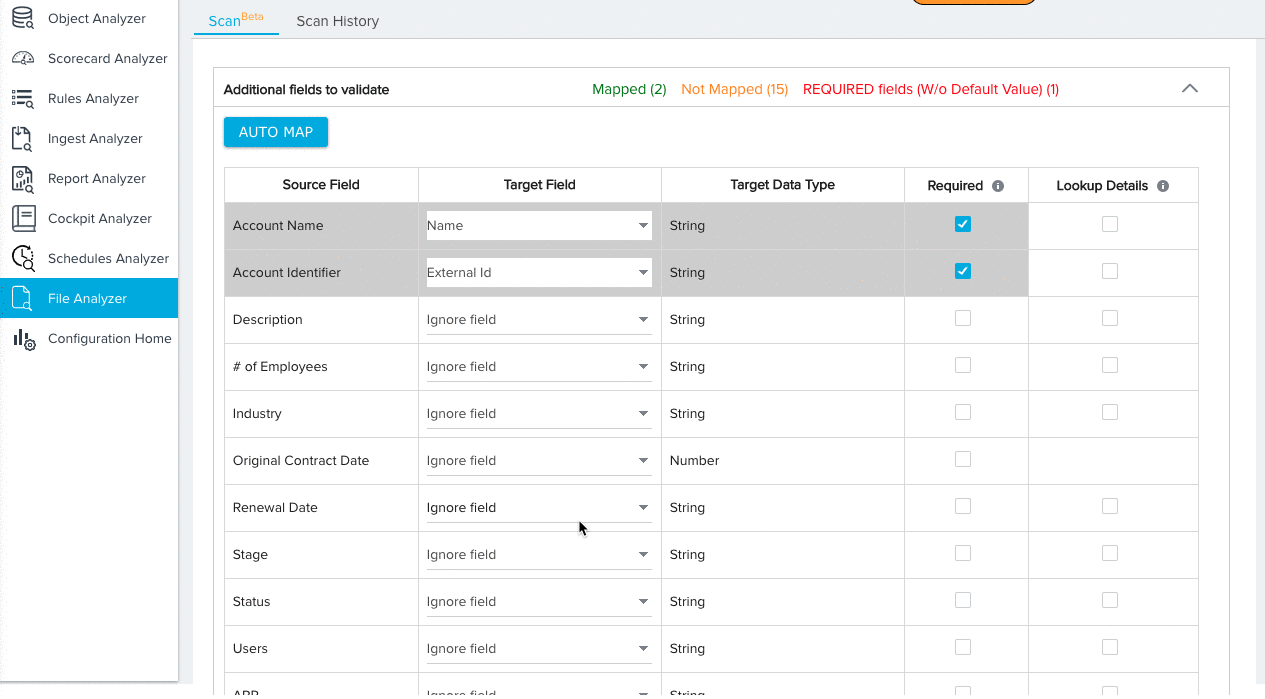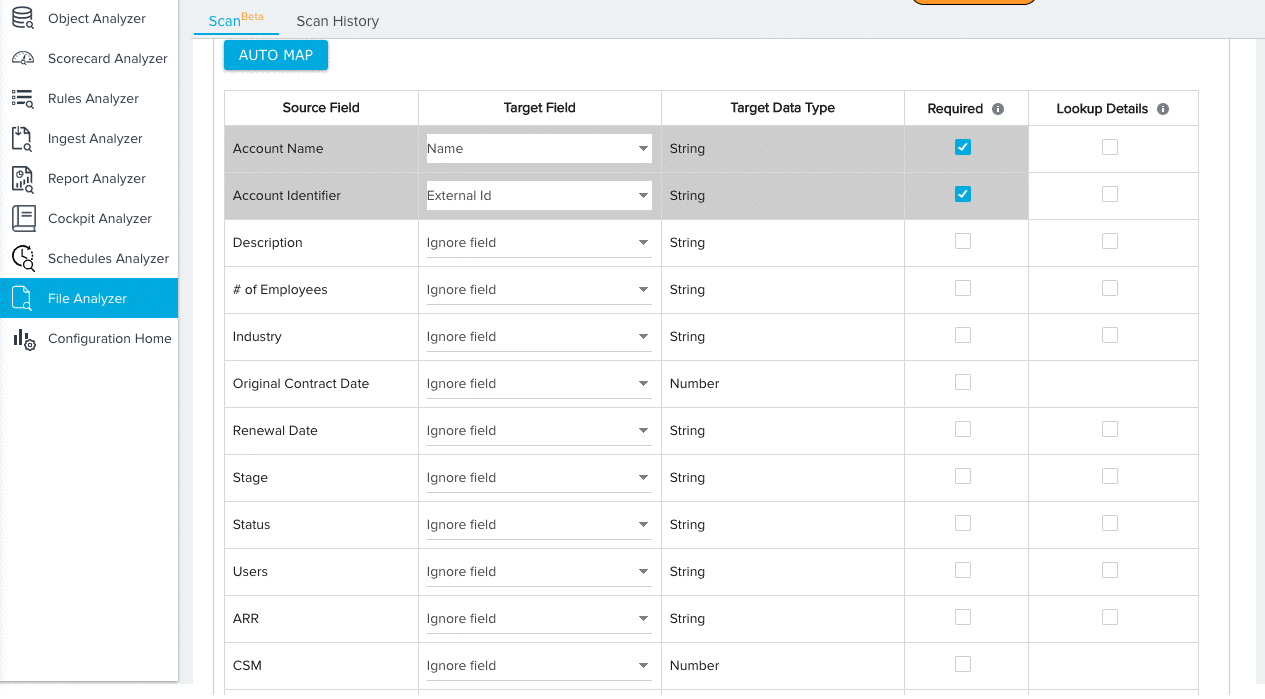
- Map key identifiers/required fields based on the dataset you selected. For more information on the specific mappings required for each dataset, refer to Dataset Key Identifiers. For our tutorial, we’ll need to make the following selections for the Company Data Model:
- A field from both the Source File and Company Object to identify each Company record.
- A field from the Source File to identify the name of each company record.
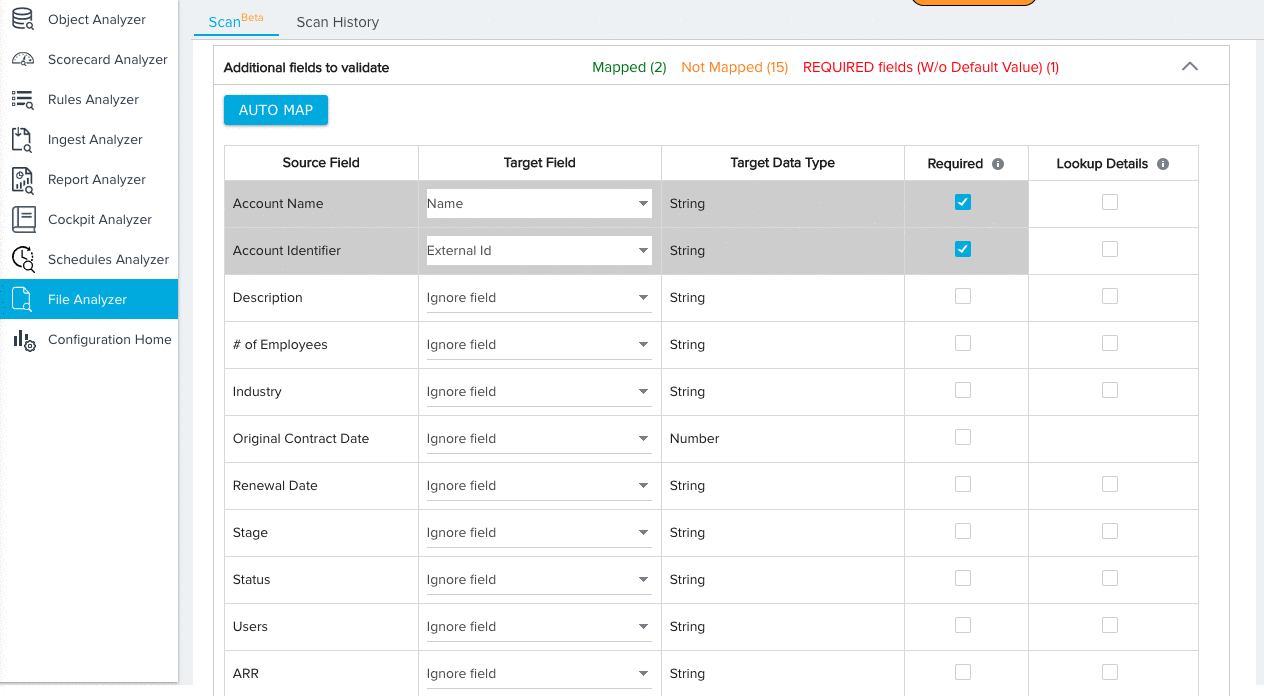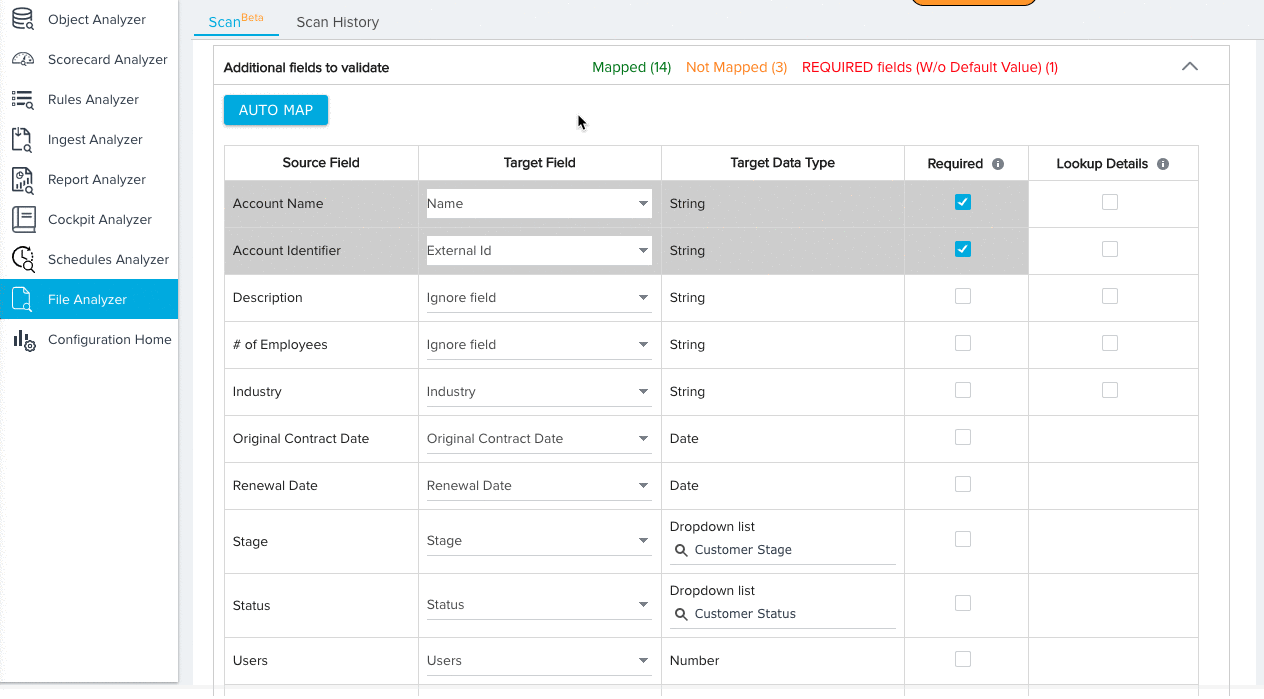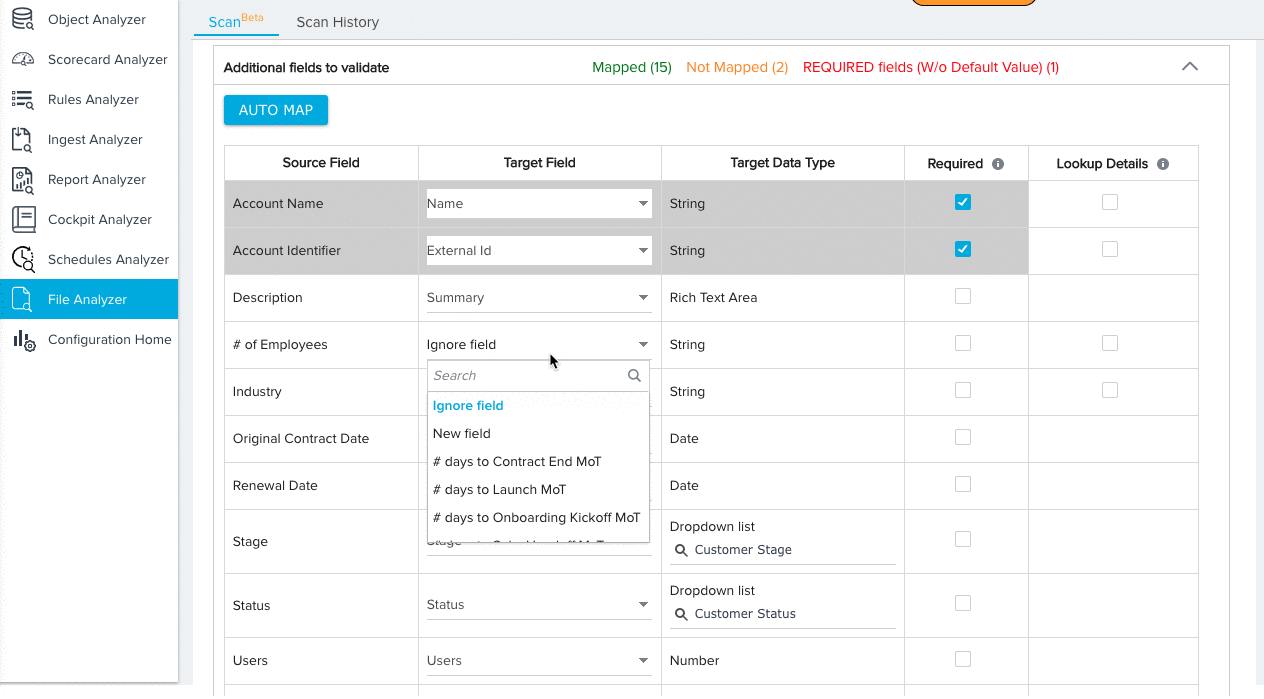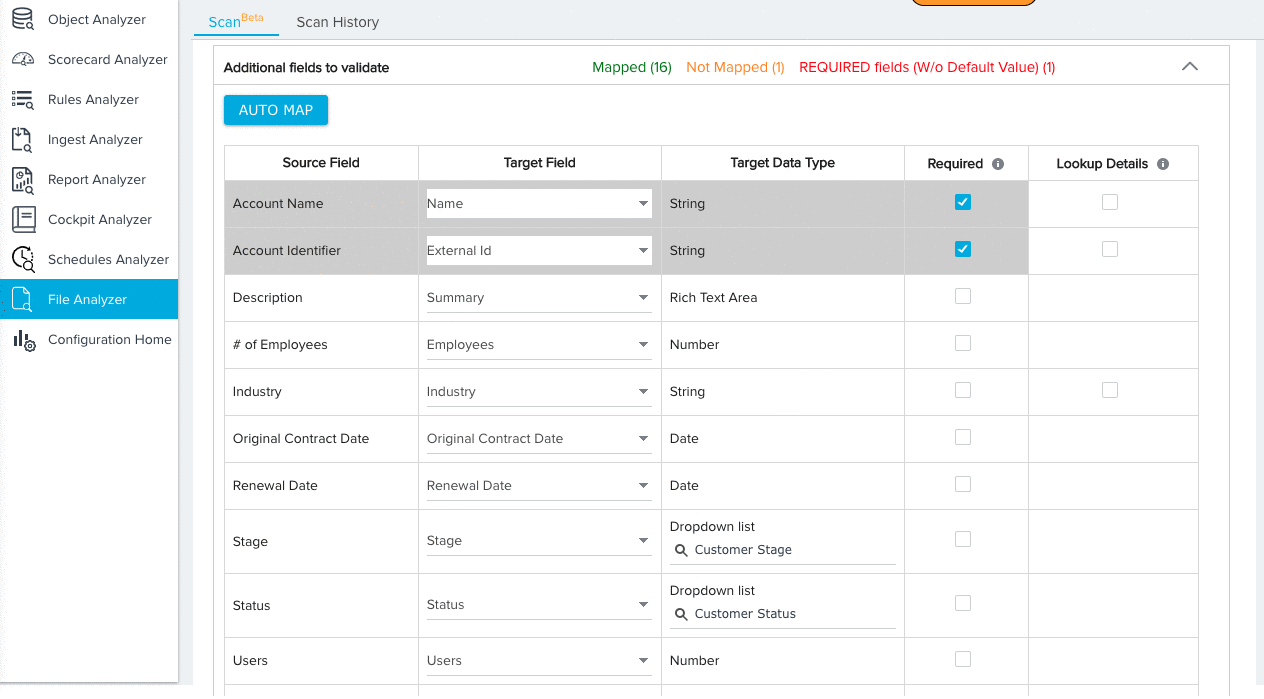
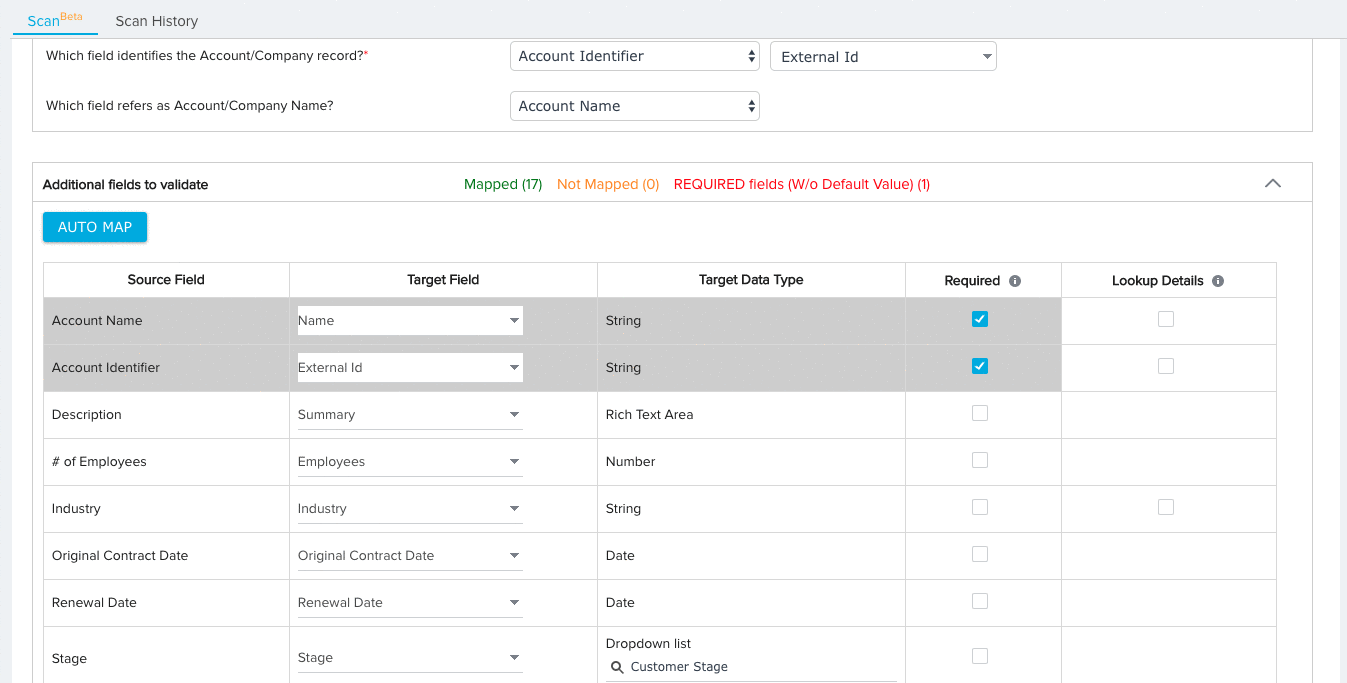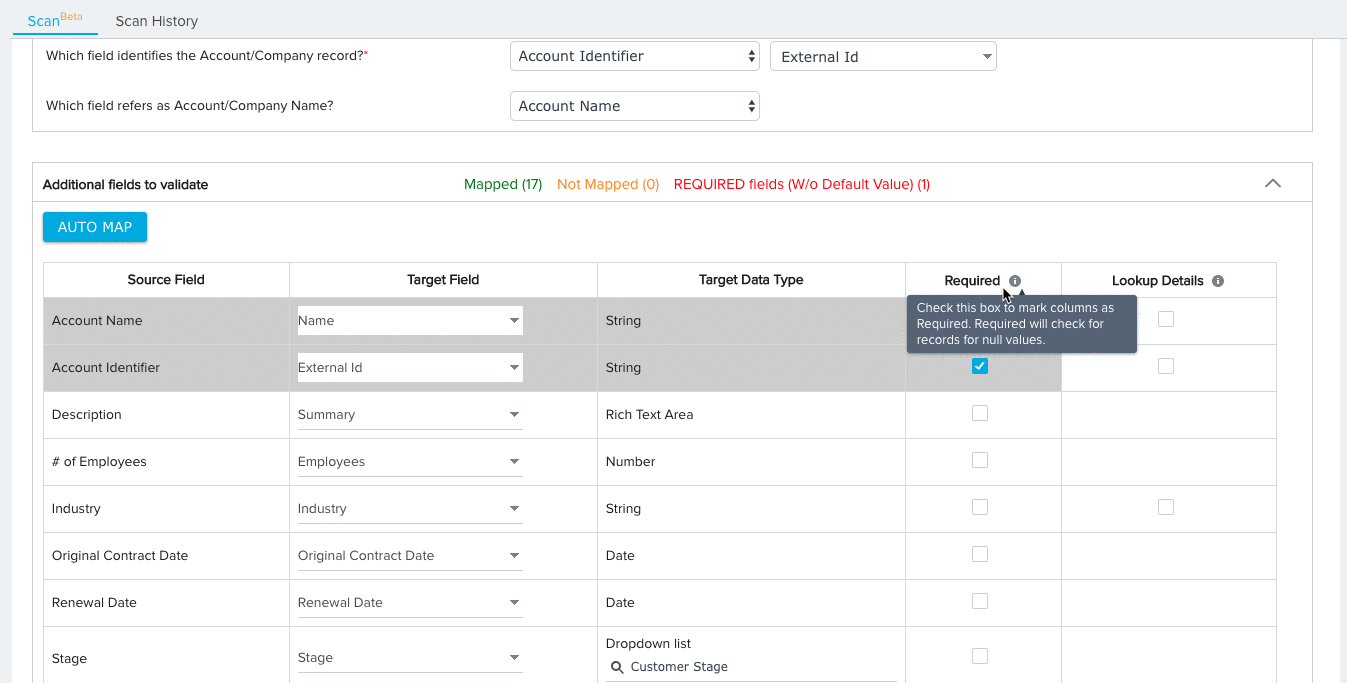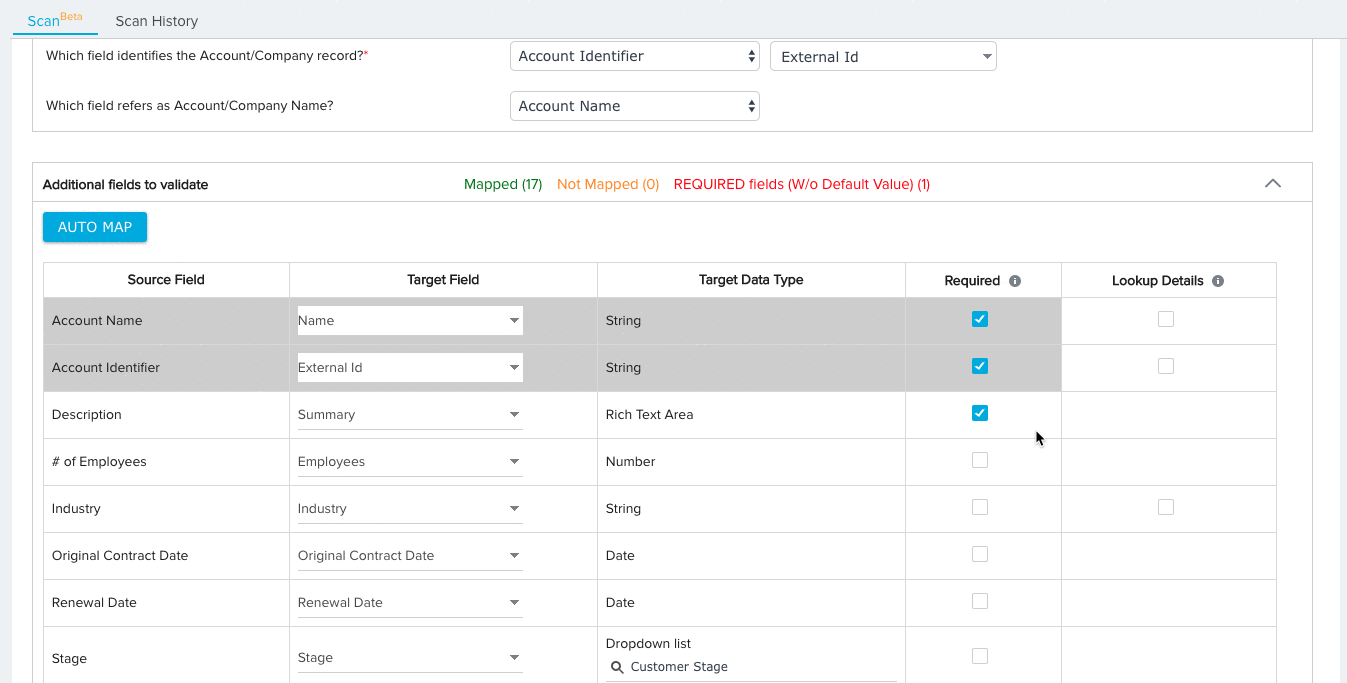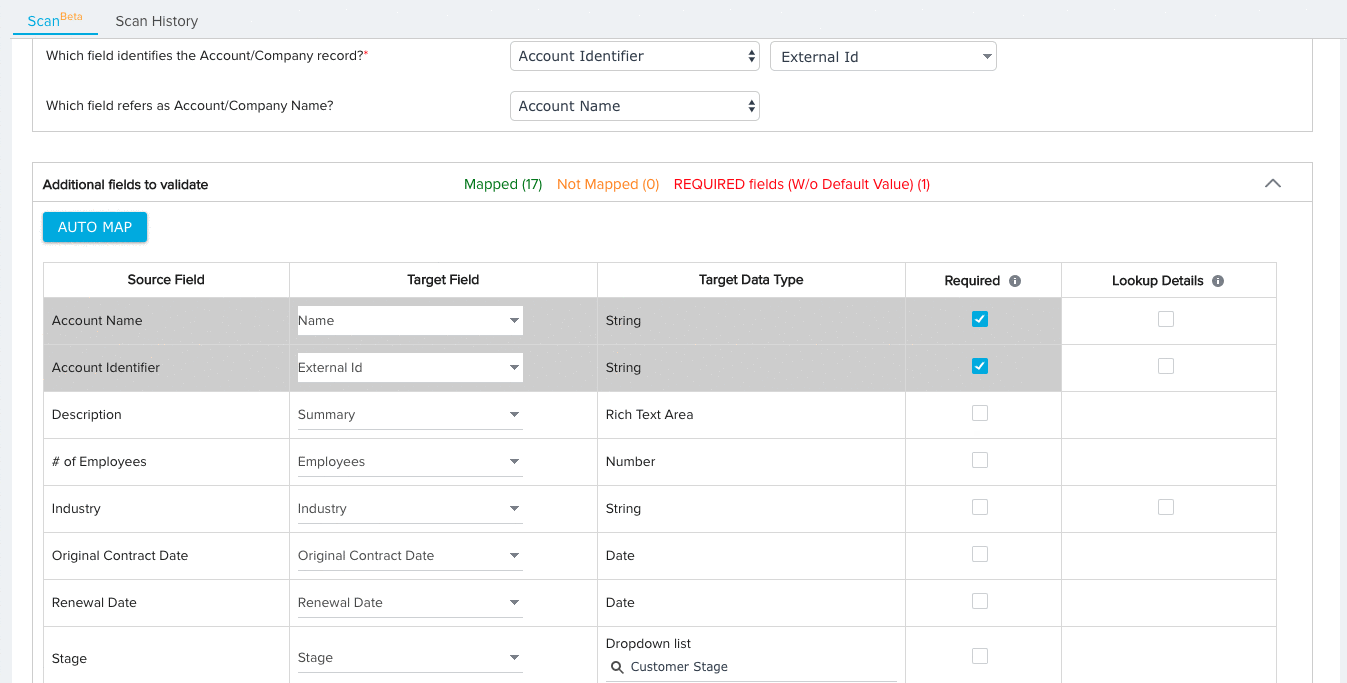
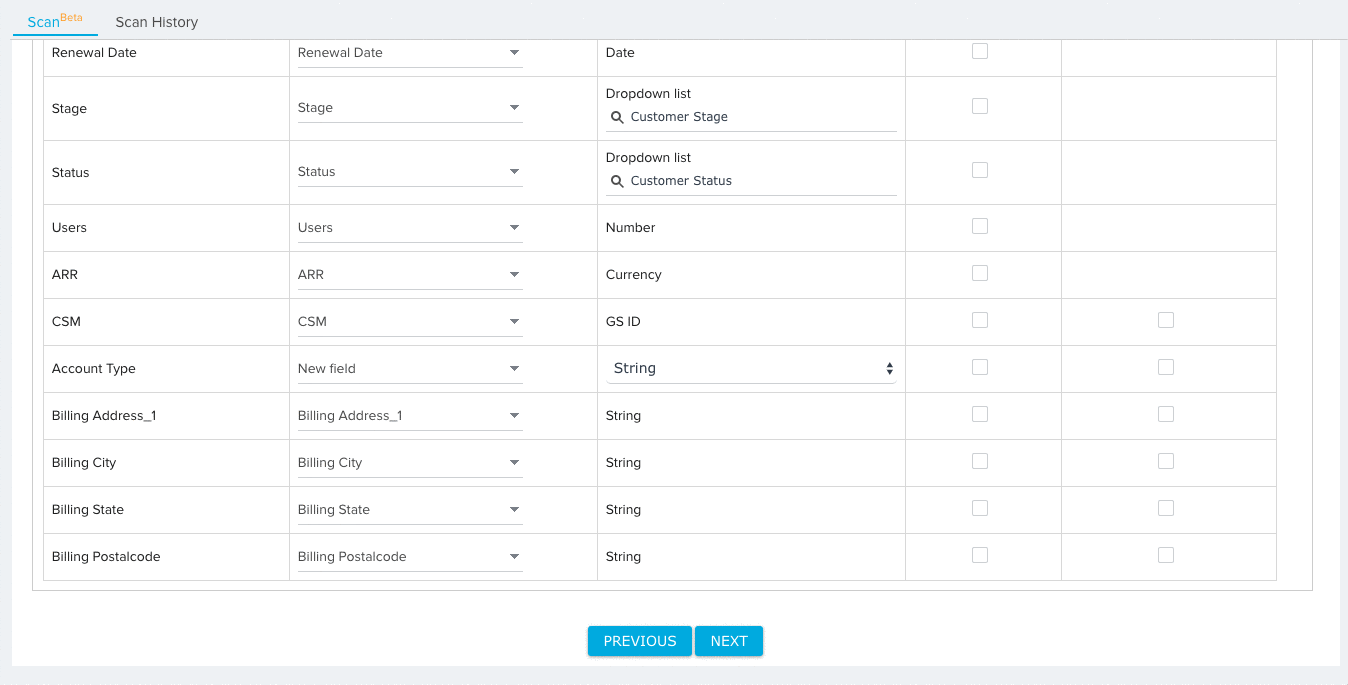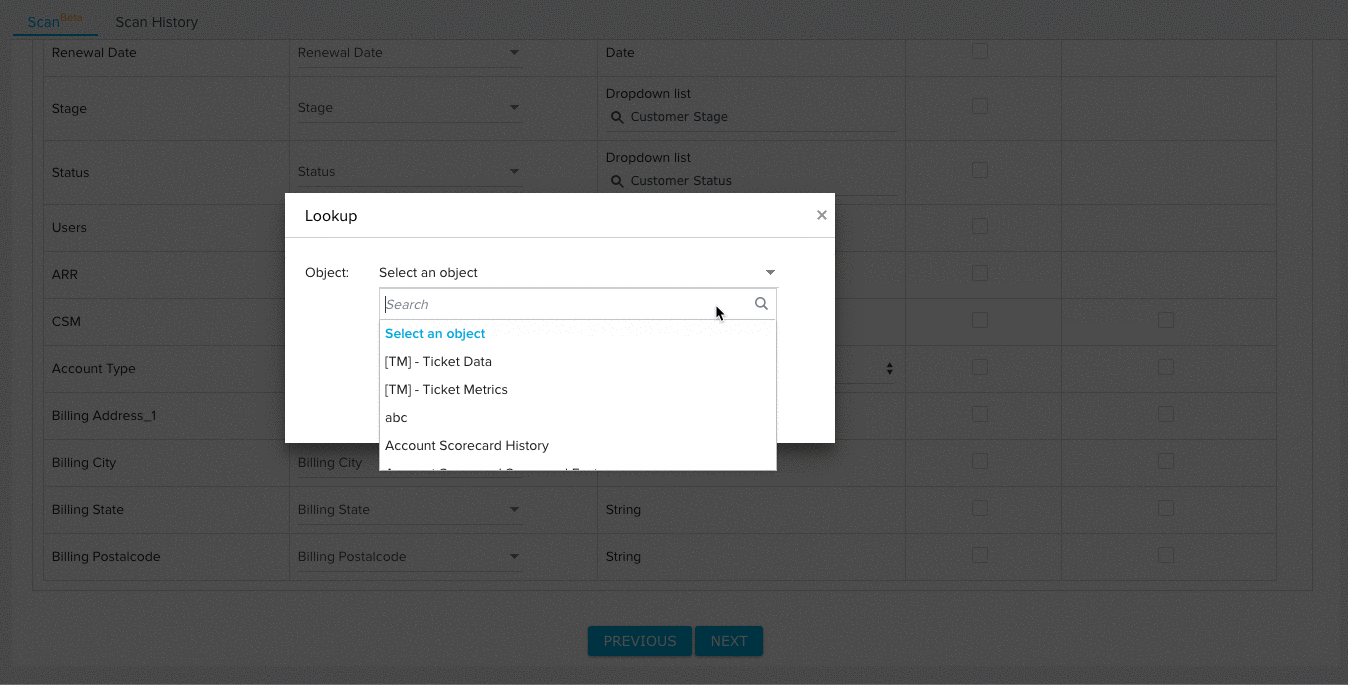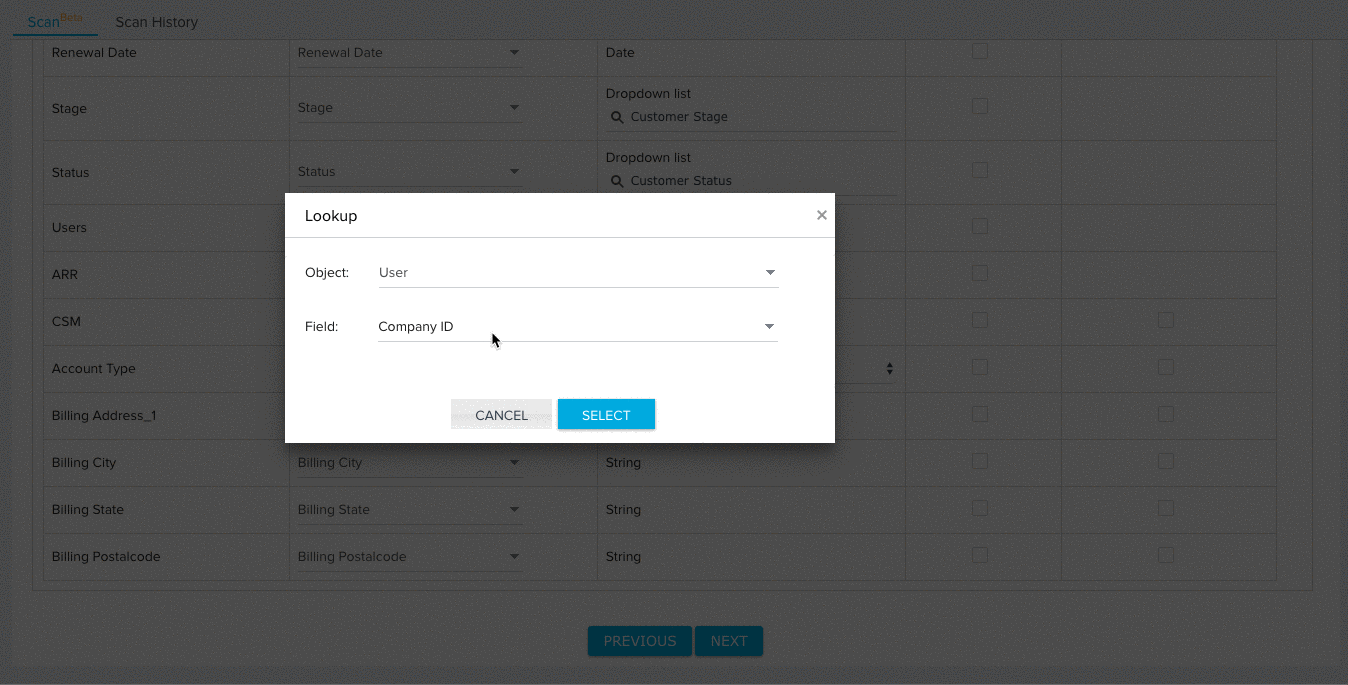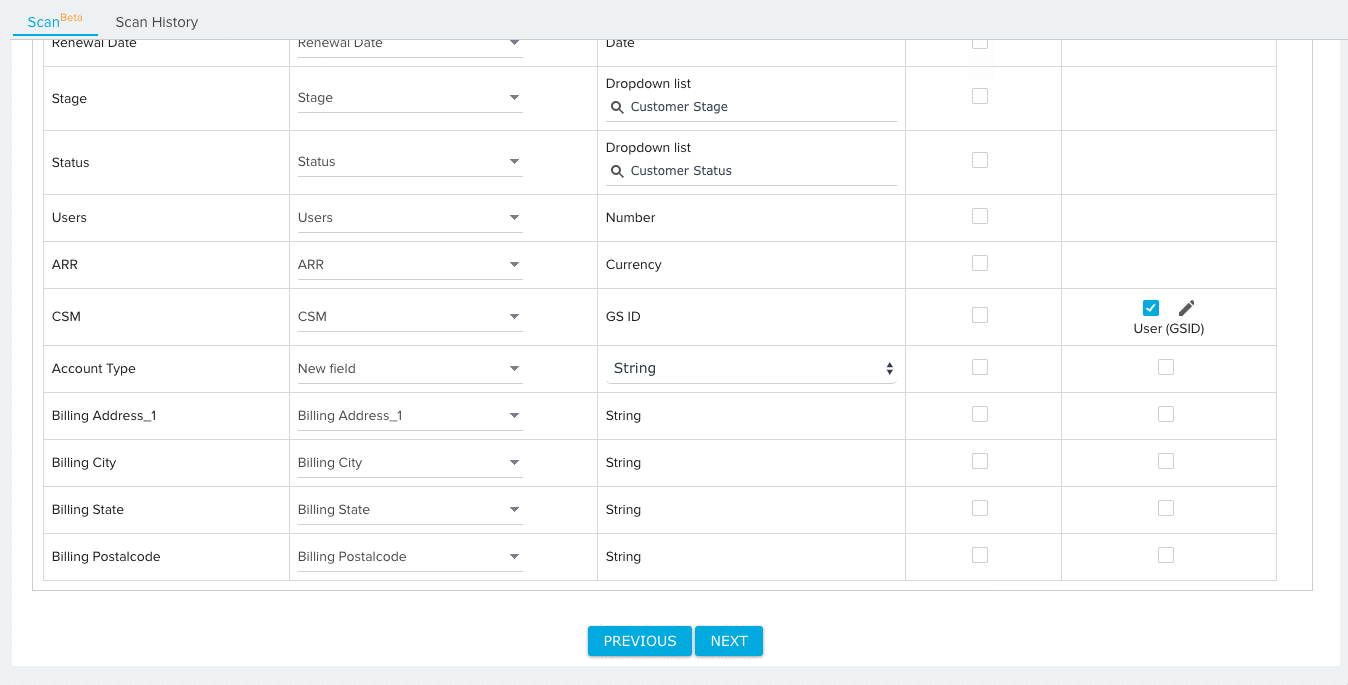
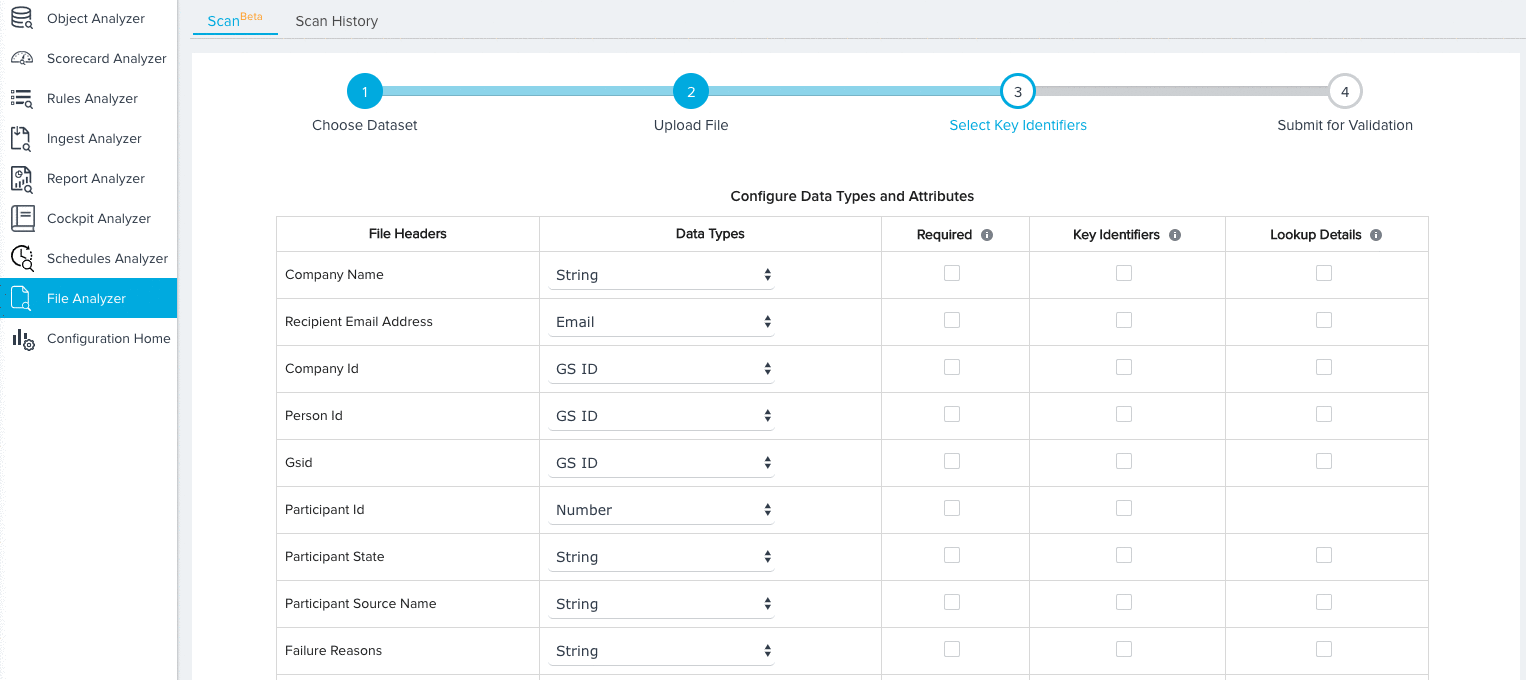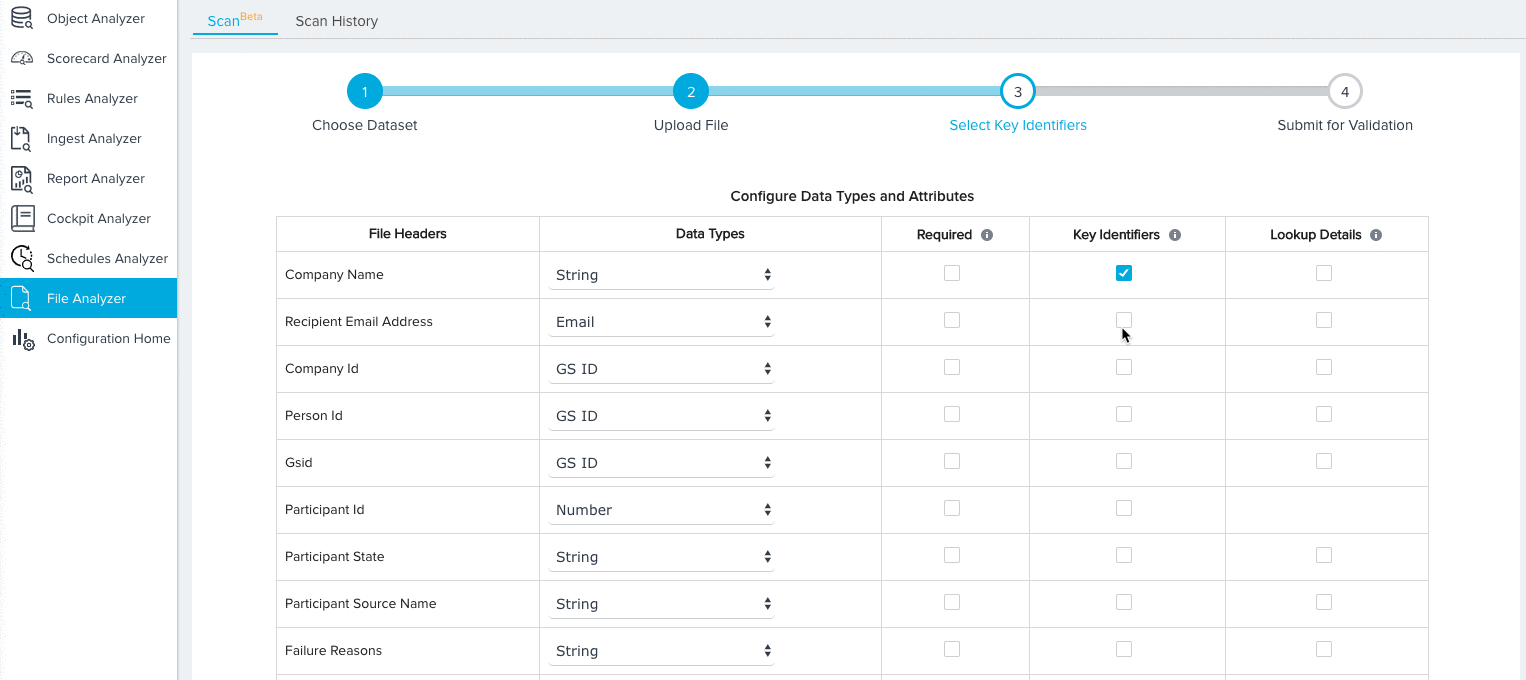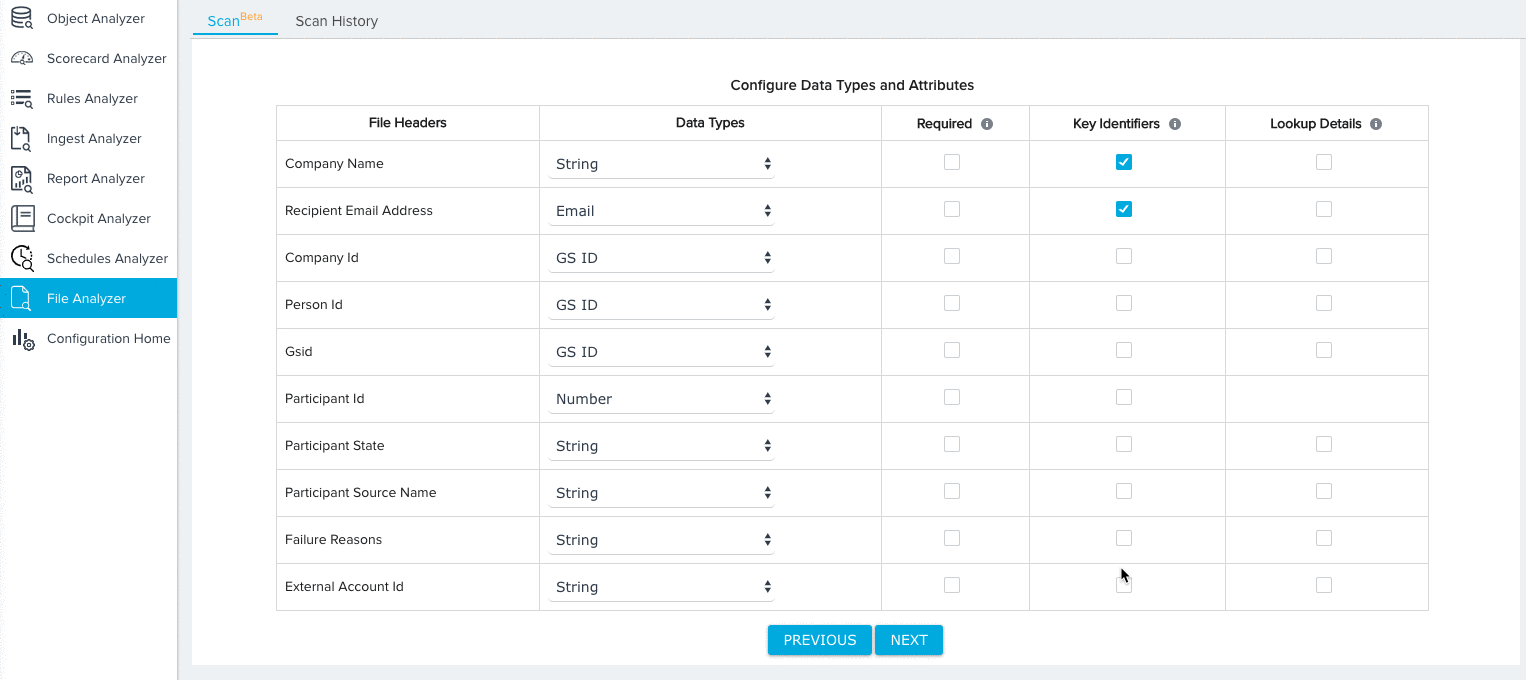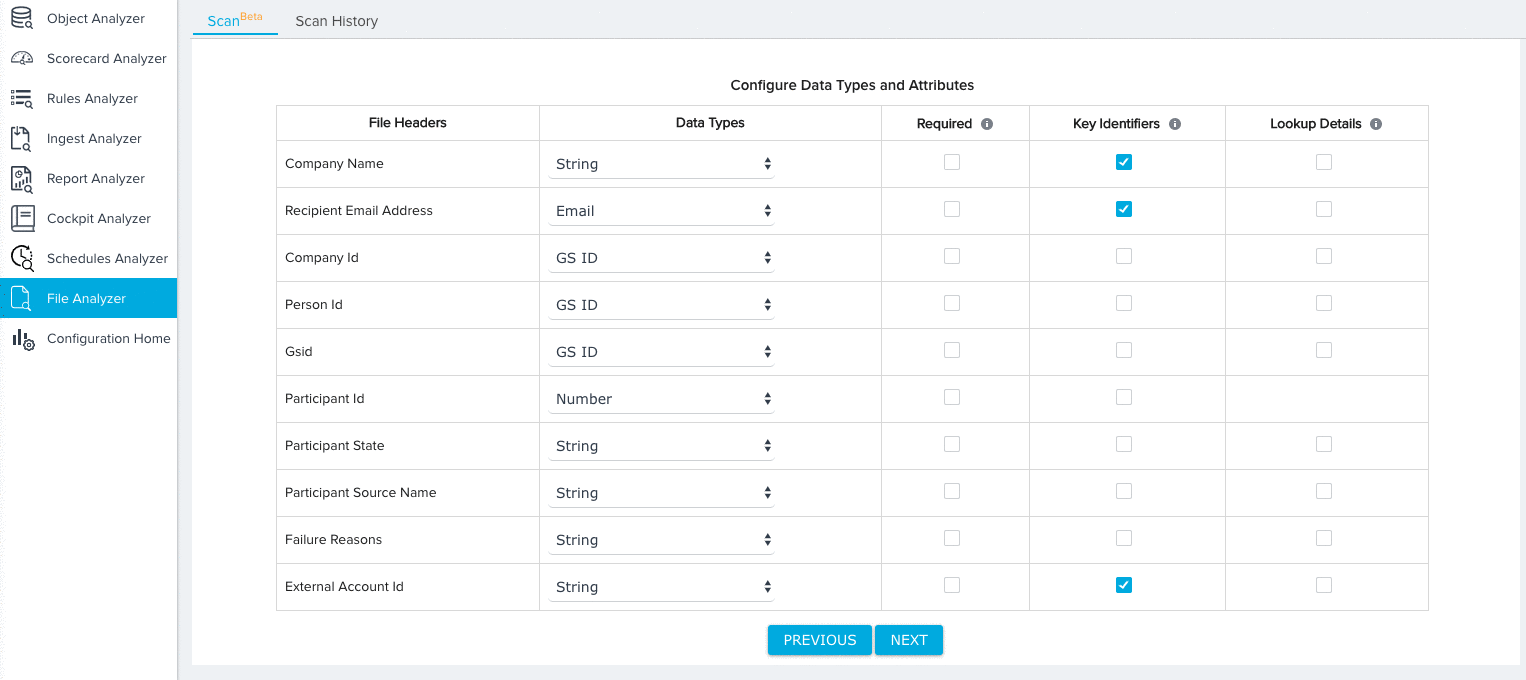
- Expand the additional fields section and map any remaining Source Fields to Target Fields. By default, the Ignore Field option will be selected for all field mappings. Source fields with the Ignore Field selection will not be considered for validation.
- (Optional) Click AUTO MAP to instantly map each source field to a target field with an identical name.
- Manually map any remaining fields.
- (Optional) Select the mapping option New Field for source fields that you would like to add to the target object. You can configure the data type for the new field after selecting this option.
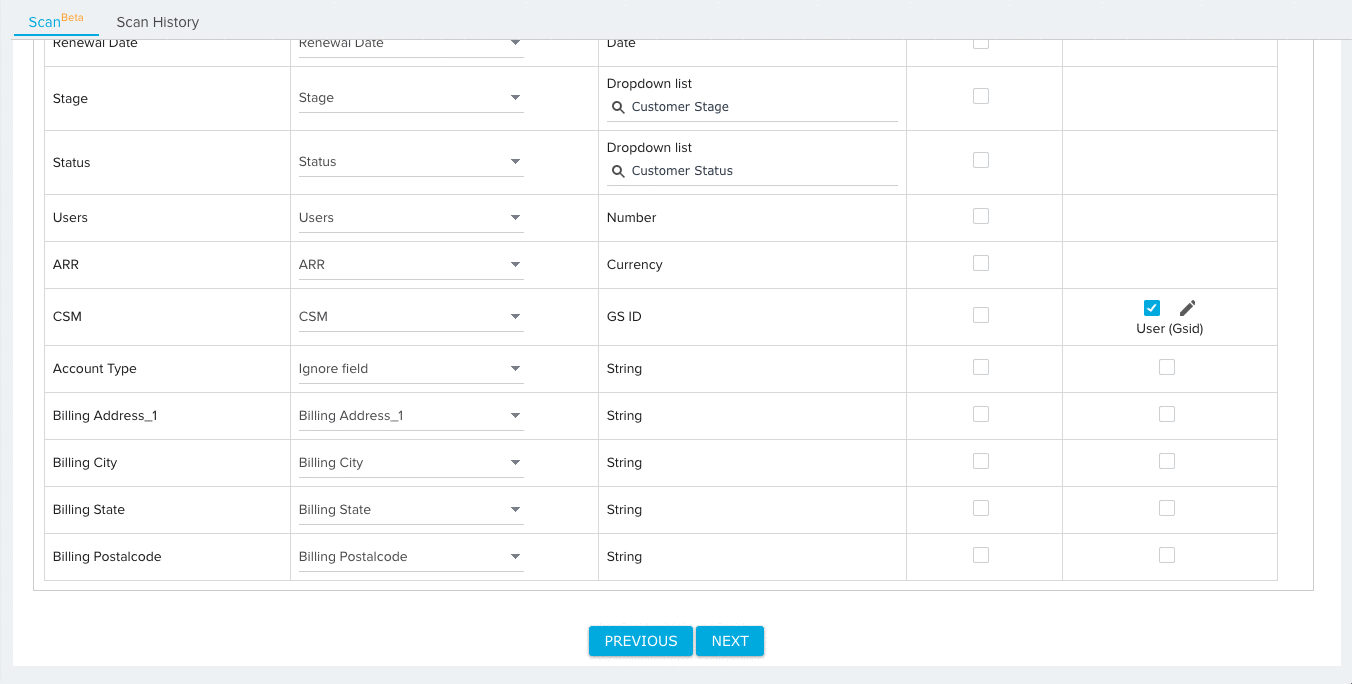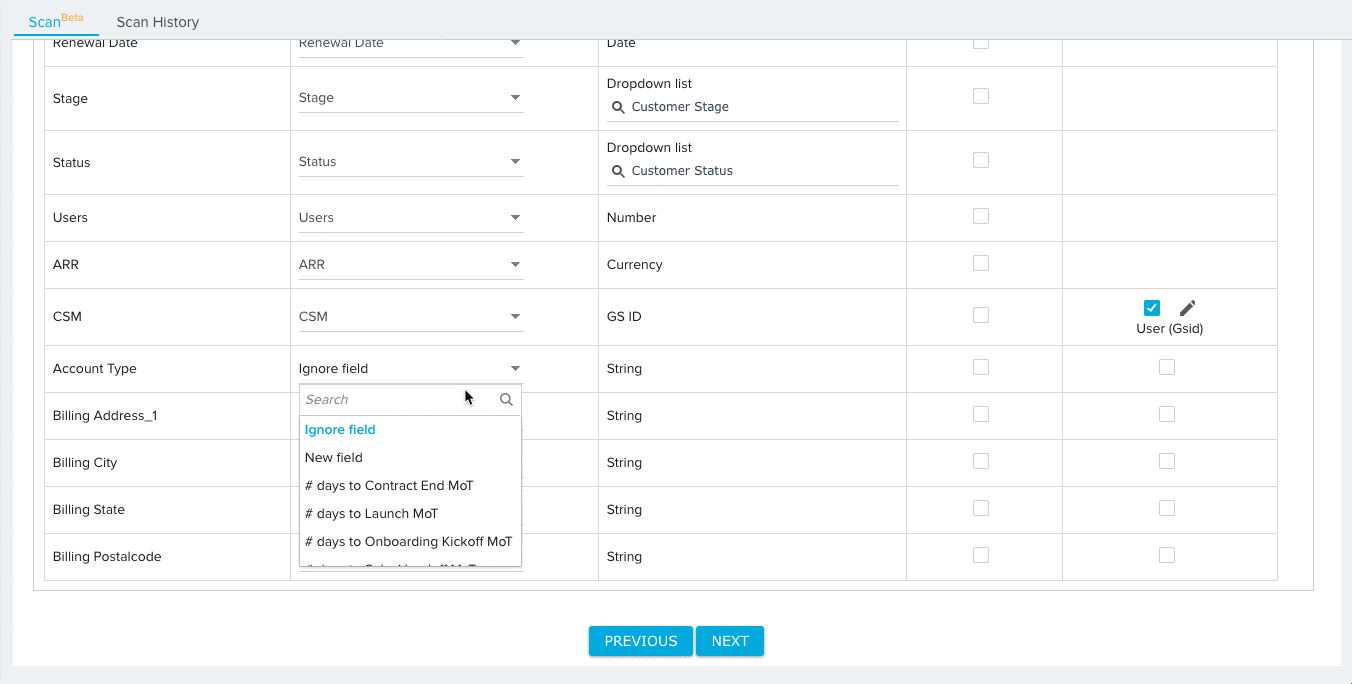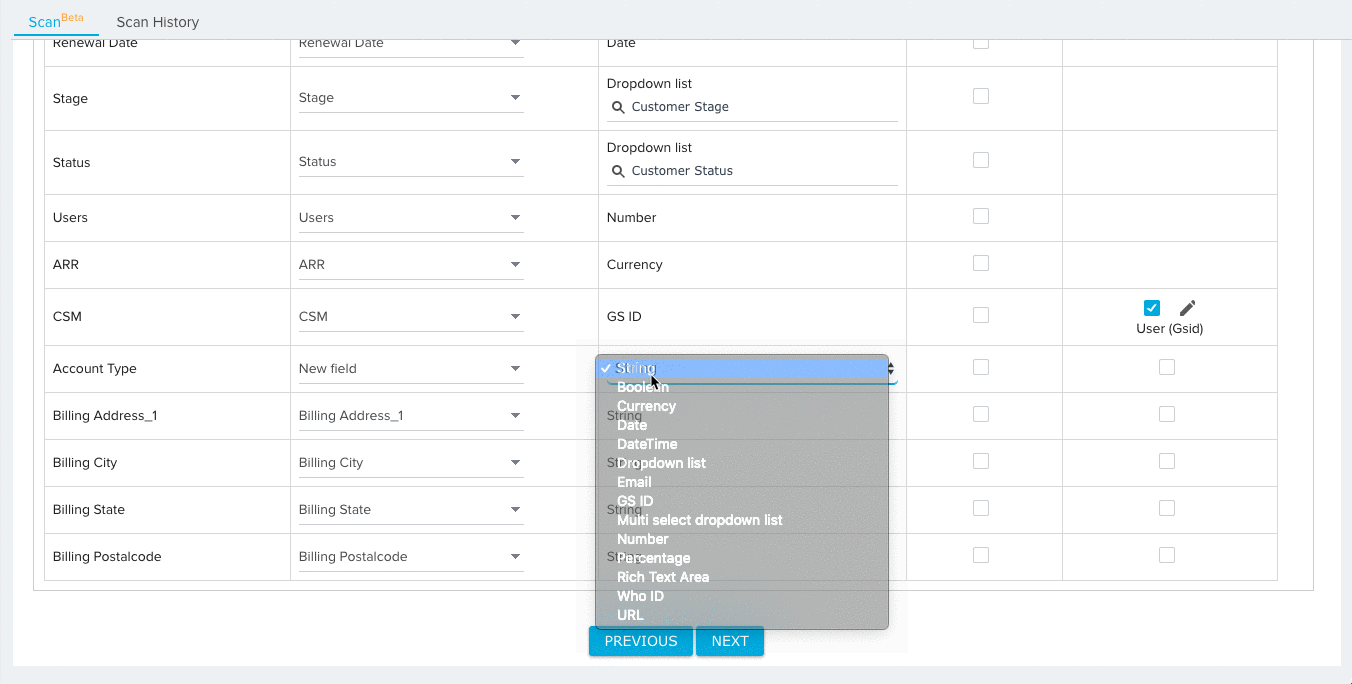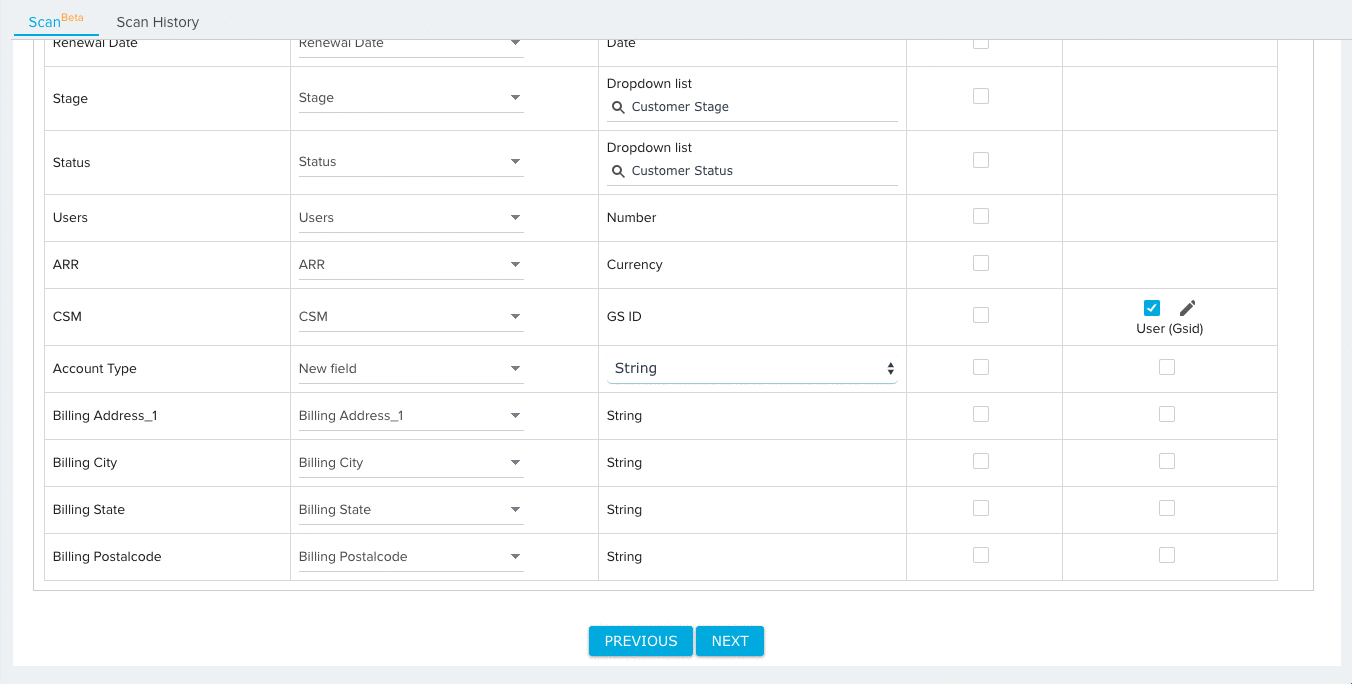
- (Optional) Click the checkbox under the Required column for any field you wish the File Analyzer to consider Required. When the file is scanned, the File Analyzer will check for null values in required fields for each record.
Note: The Key Identifier fields for each data set will always be considered required.
- (Optional) Click the checkbox under the Lookup Details column to add lookup details between the field and a field in another object. For fields with added lookup details, the File Analyzer validates the data of each field for existence in the looked up object.
- Click Next
- Review the scan points selected for file analysis. By default, all scan points will be checked, and the points Columns count mismatch, Duplicate key identifiers, and Null values on Key Identifiers can not be unchecked. For more information on scan points, refer to Scan Points.
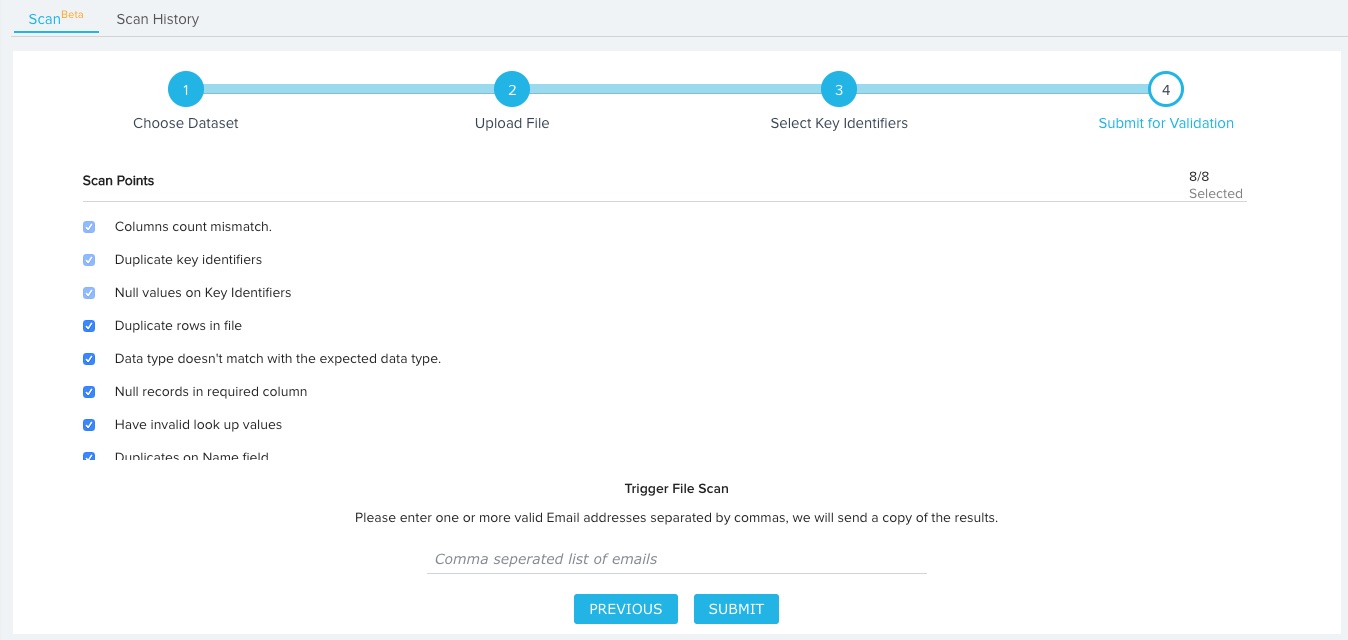
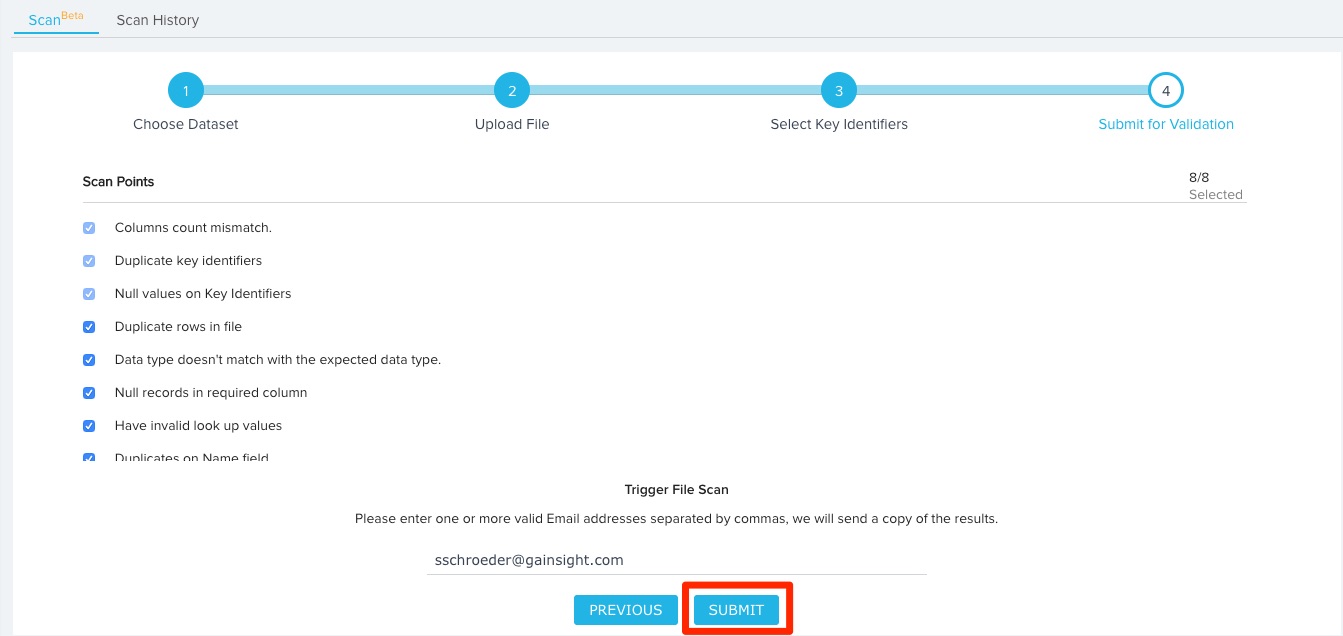
- Enter one or more valid email addresses, separated by commas, to send a copy of the analysis results.
- Click SUBMIT to initiate the file validation process.
Dataset Key Identifiers
Each dataset has different required mappings you must complete in the Select Key Identifiers step. These mappings are defined below:
User
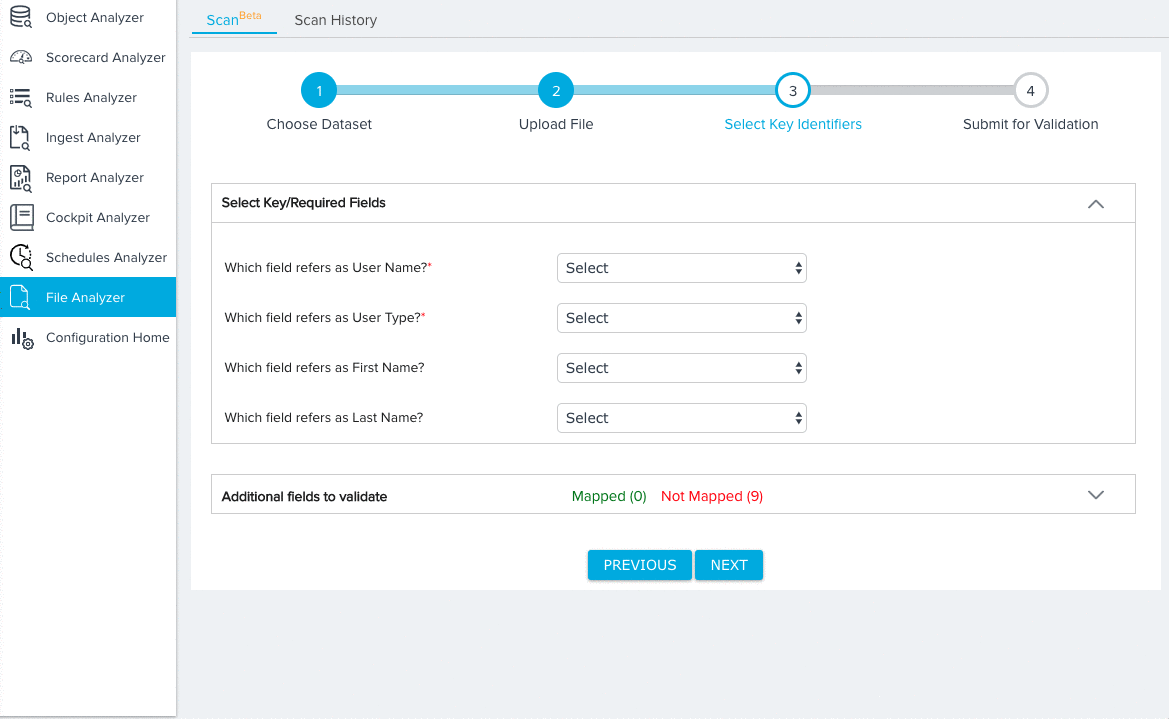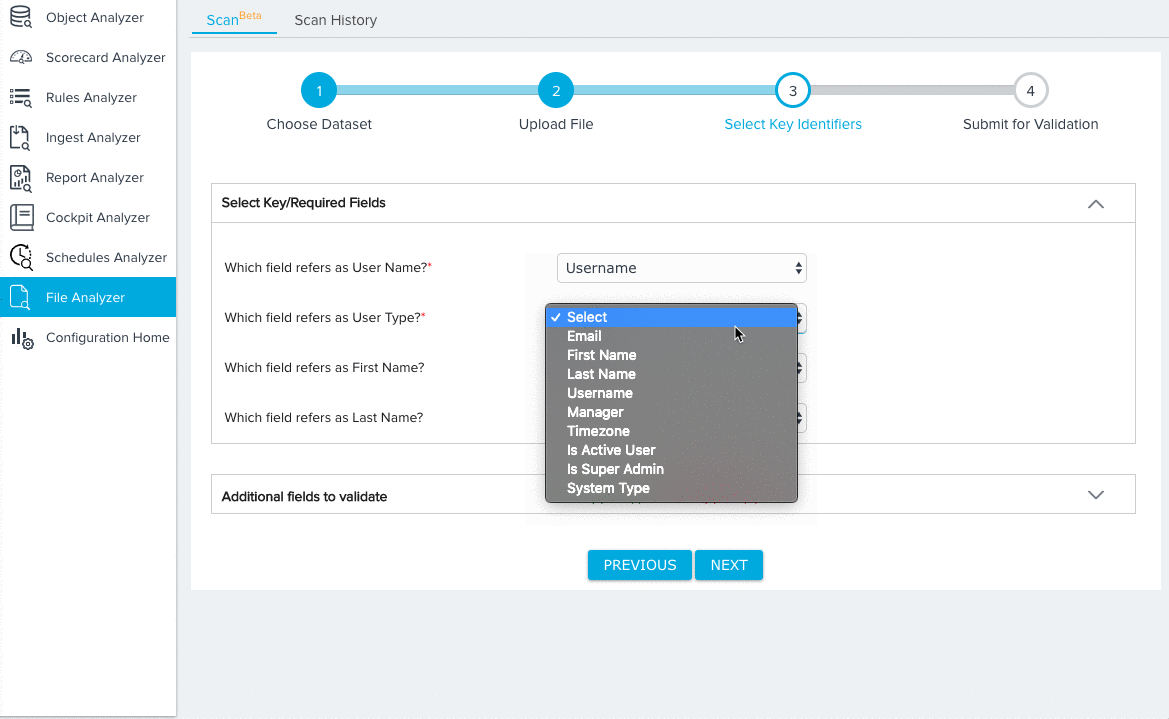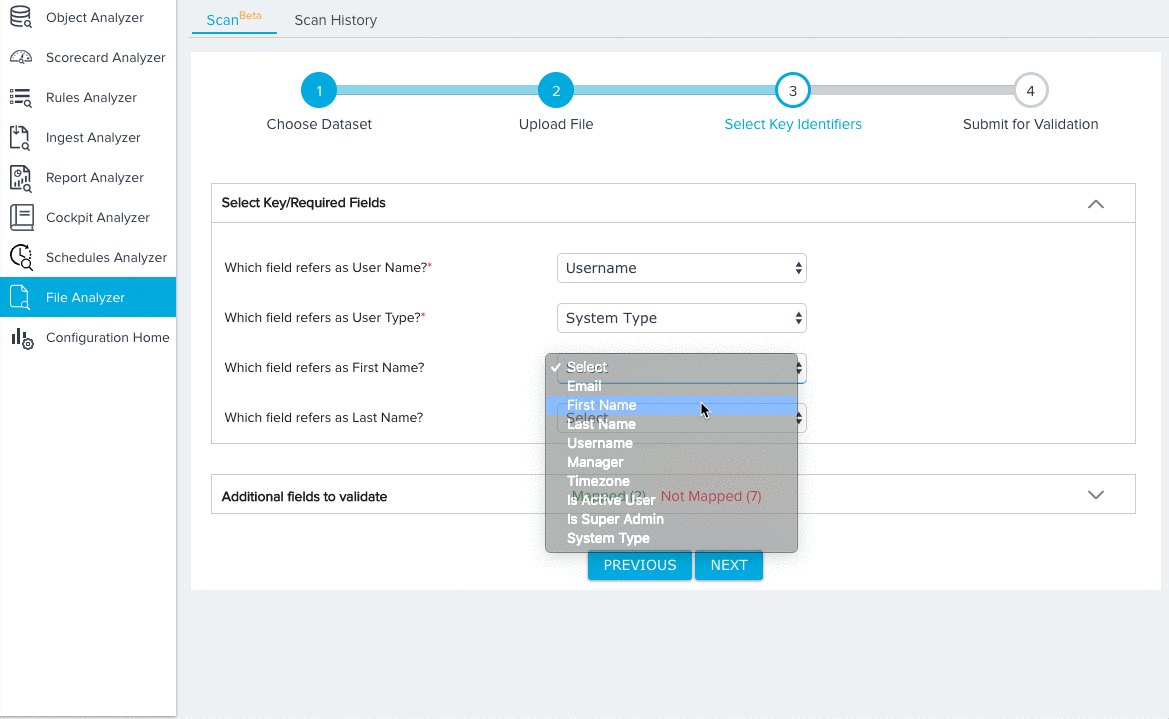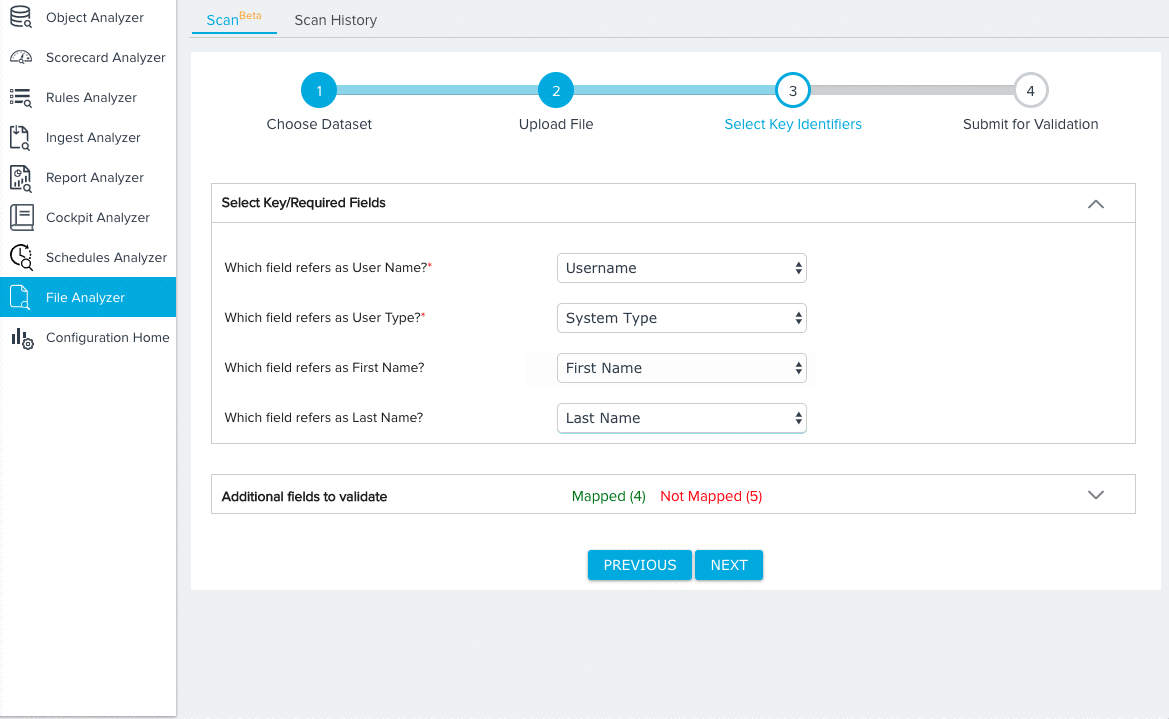
For the User dataset, you need to map fields from the source object to the following key identifiers:
- User Name (Required)
- User Type (Required)
- First Name
- Last Name
Company
For the Company dataset, you need to map fields from the source object to the following key identifiers:
- Account/Company ID (Required)
- Account/Company Name (Required)
Person
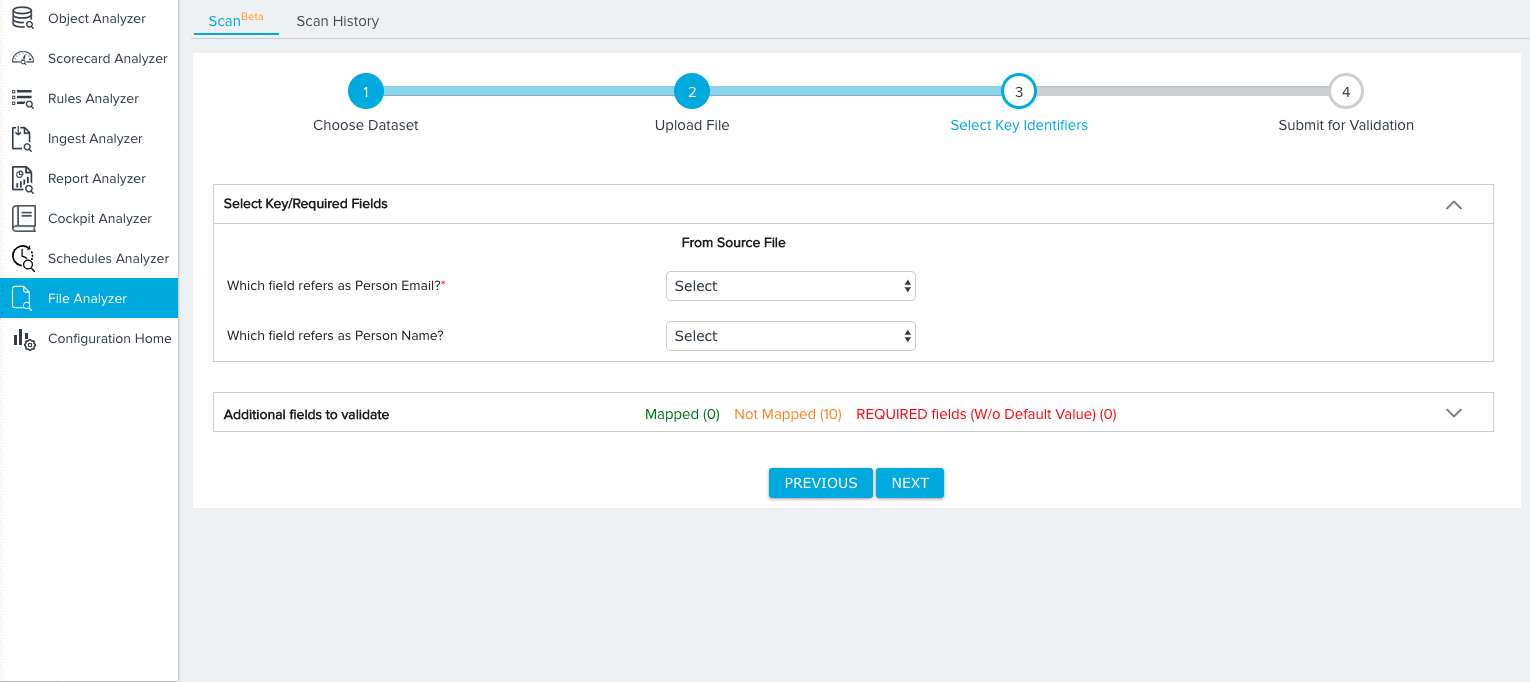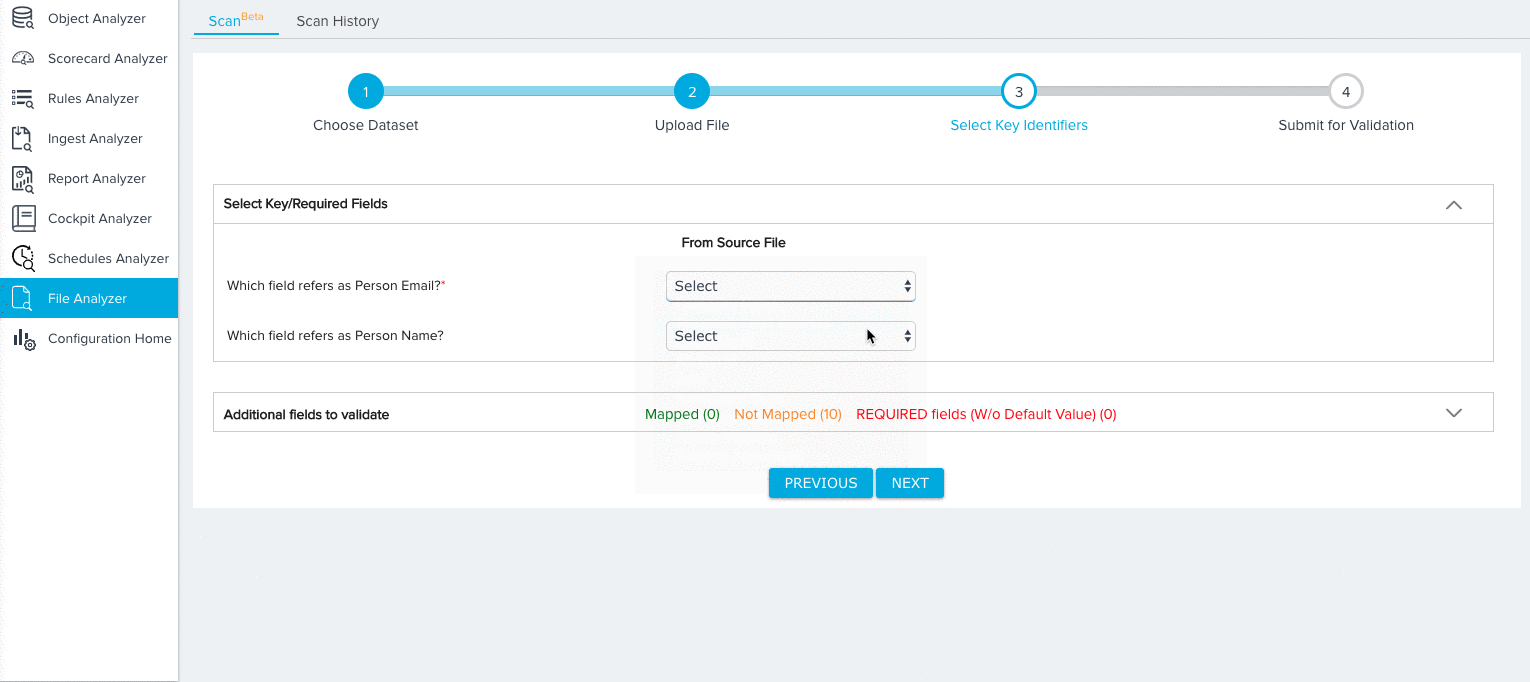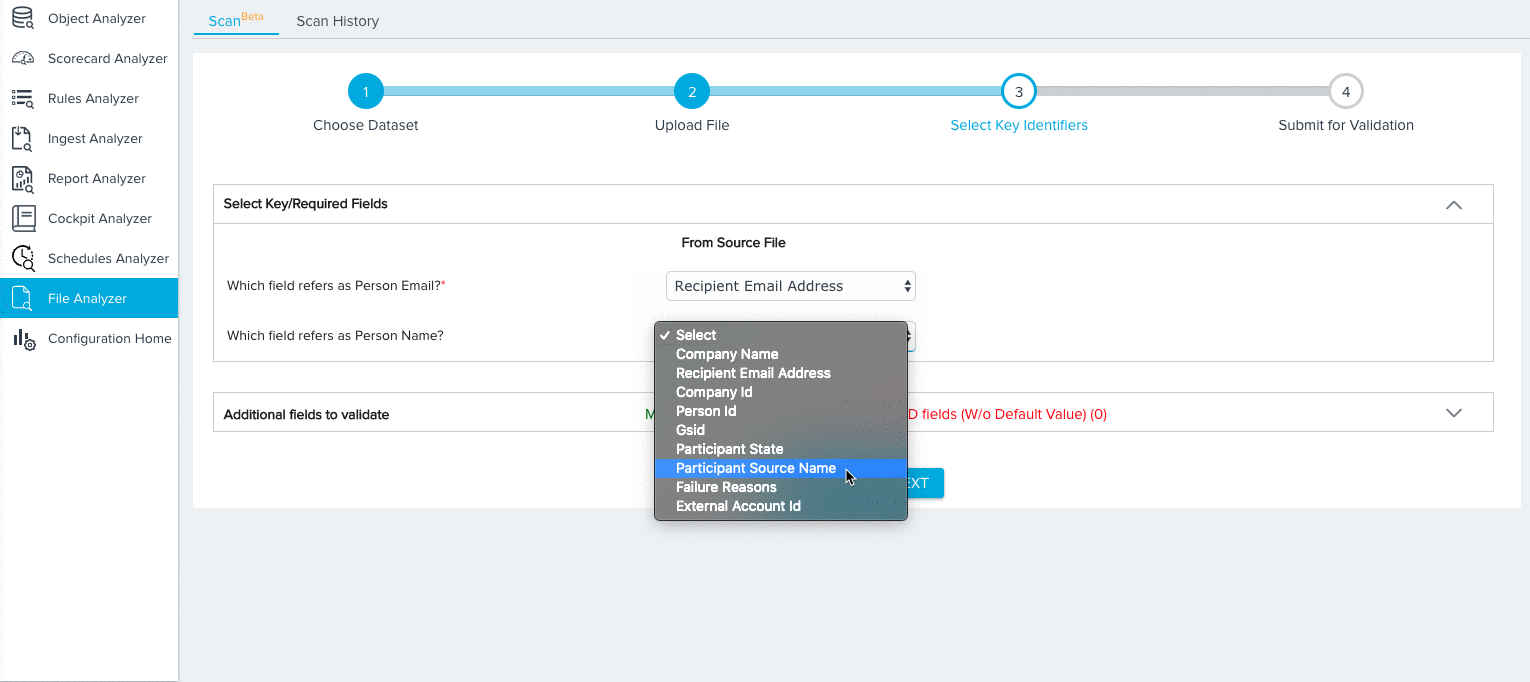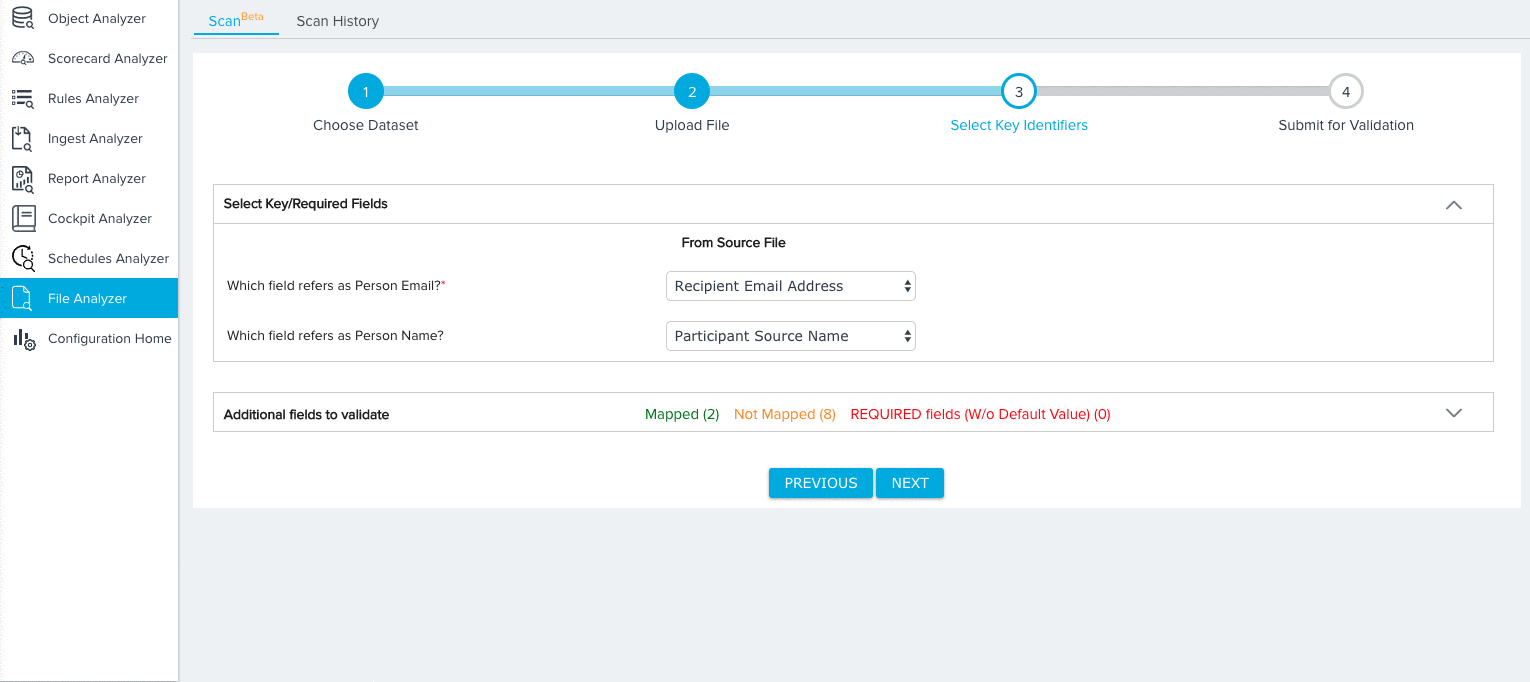
For the Person dataset, you need to map fields from the source object to the following key identifiers:
- Person Email (Required)
- Person Name
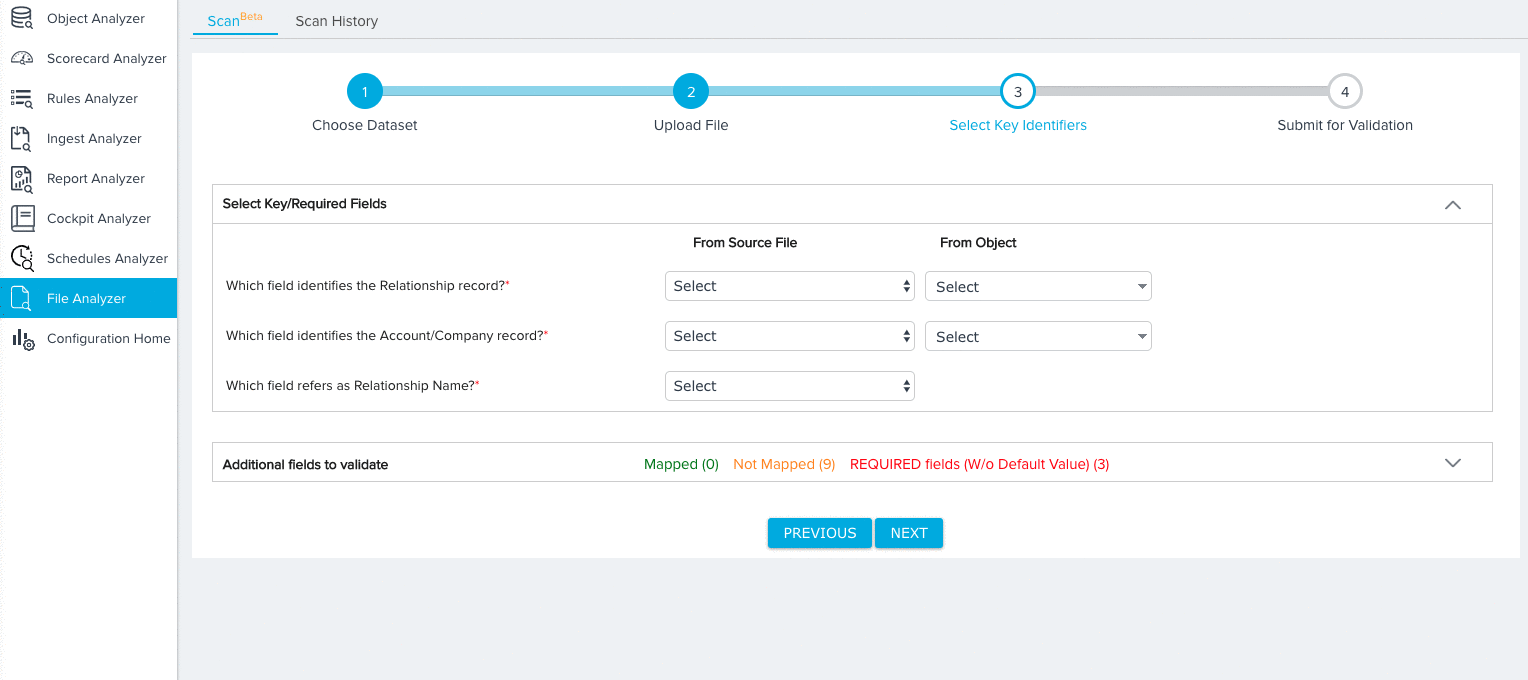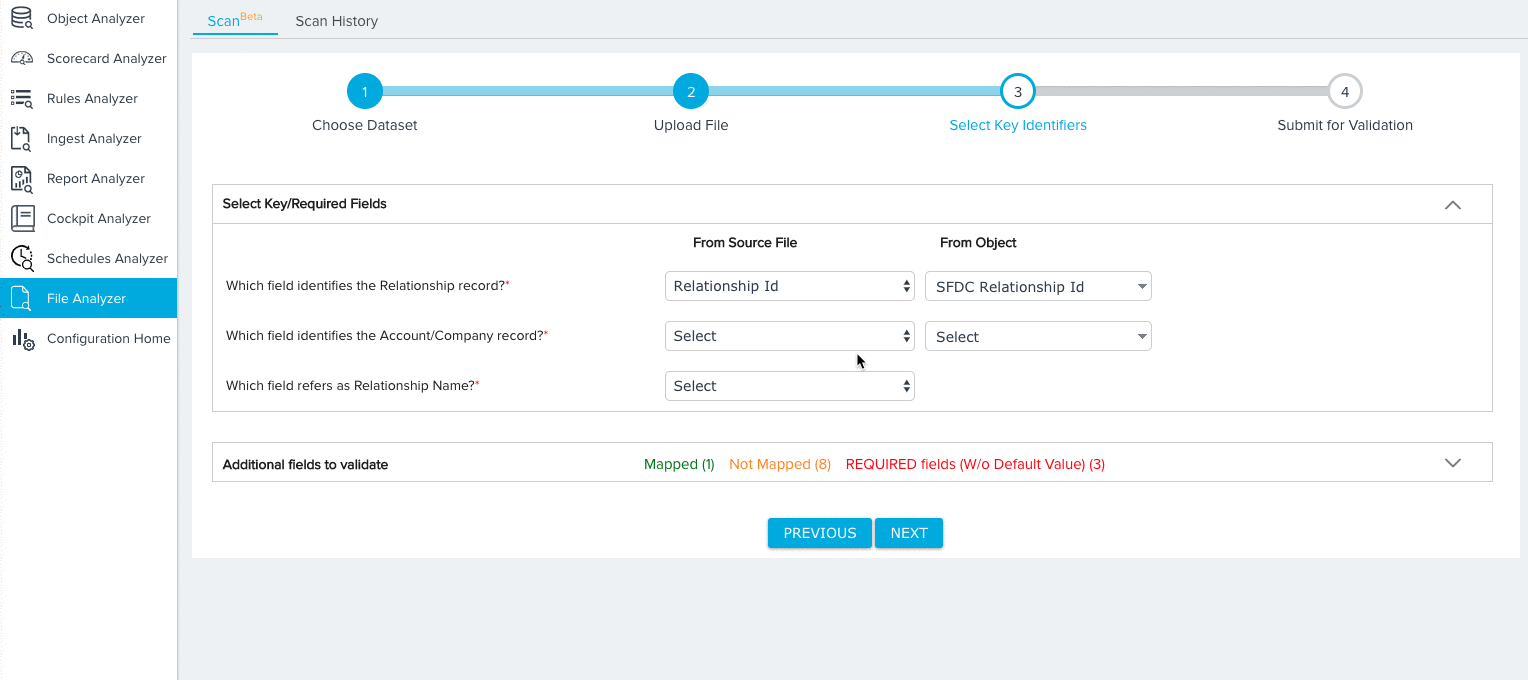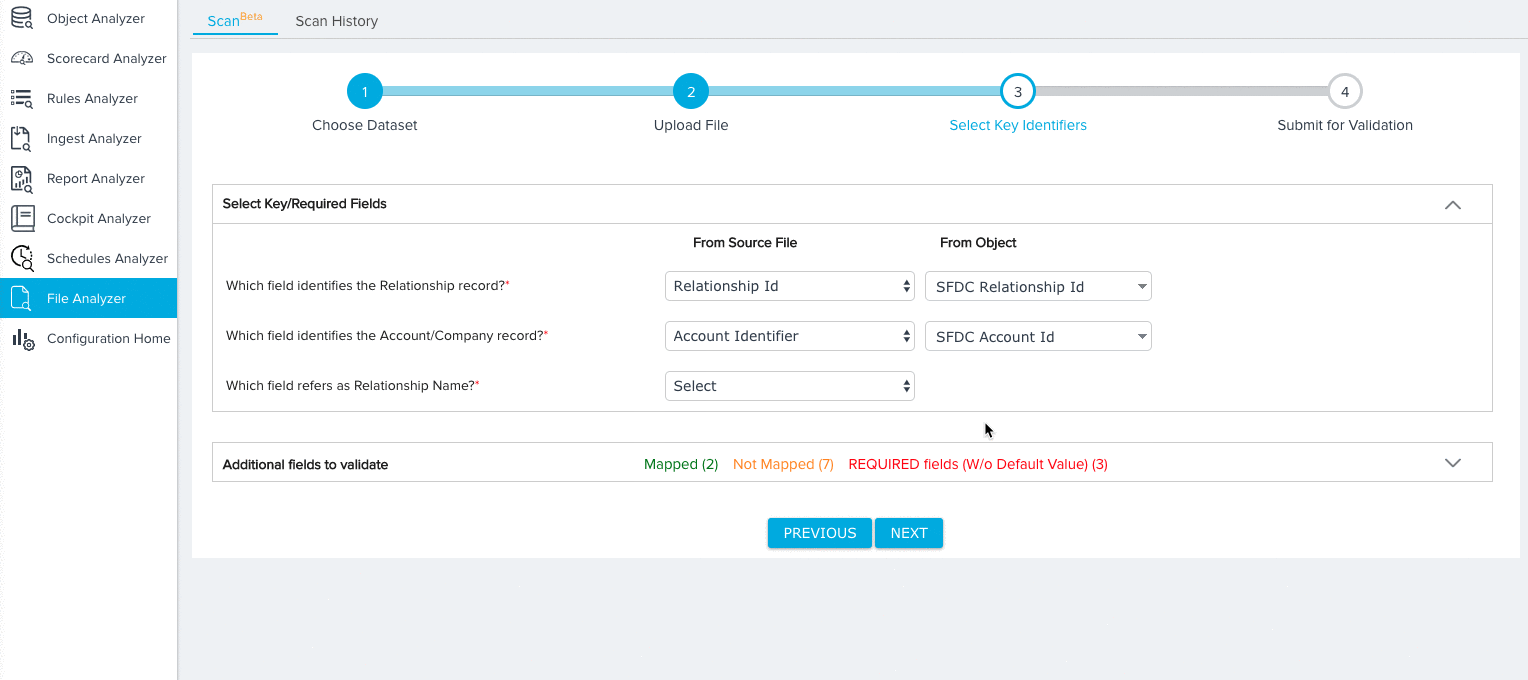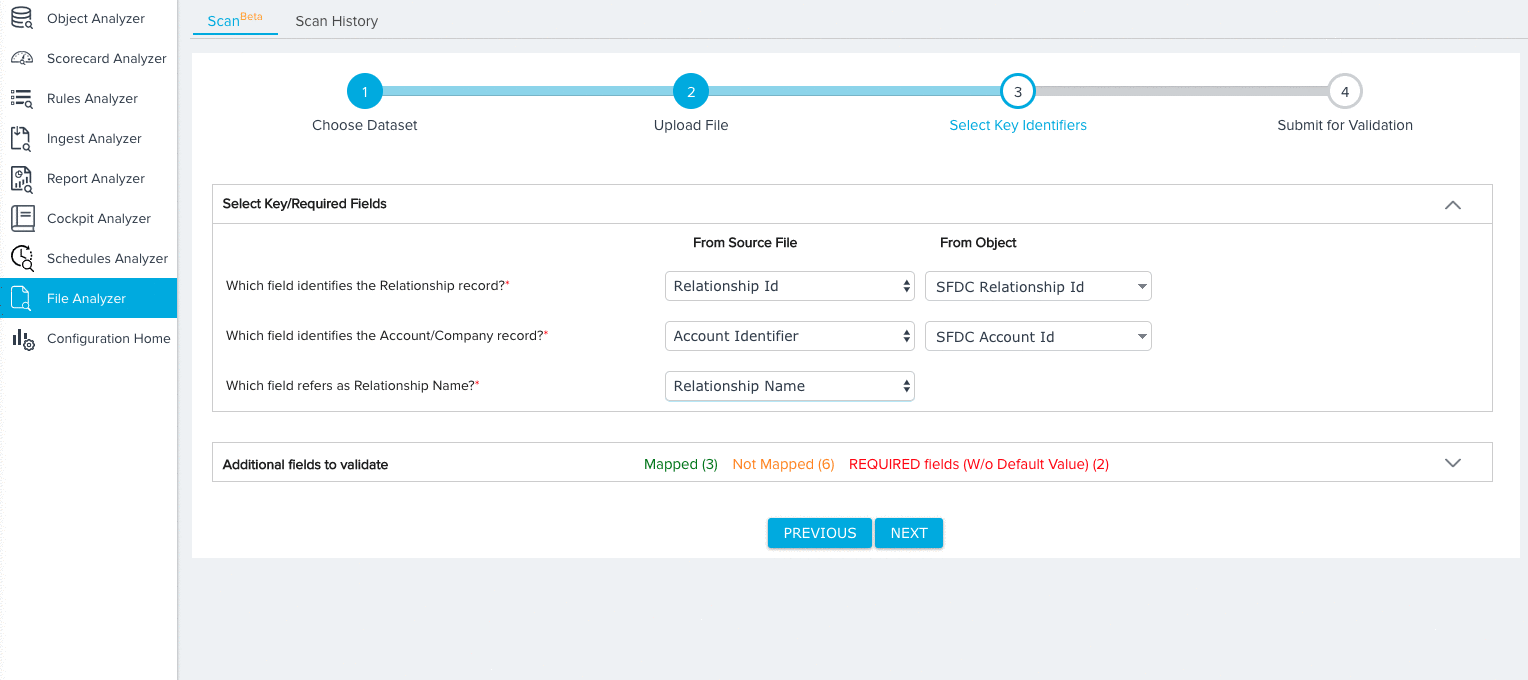
Relationship
For the Relationship dataset, you need to map fields from the source object to the following key identifiers:
- Relationship ID (Required)
- Account/Company ID (Required)
- Relationship Name (Required)
 Custom Object
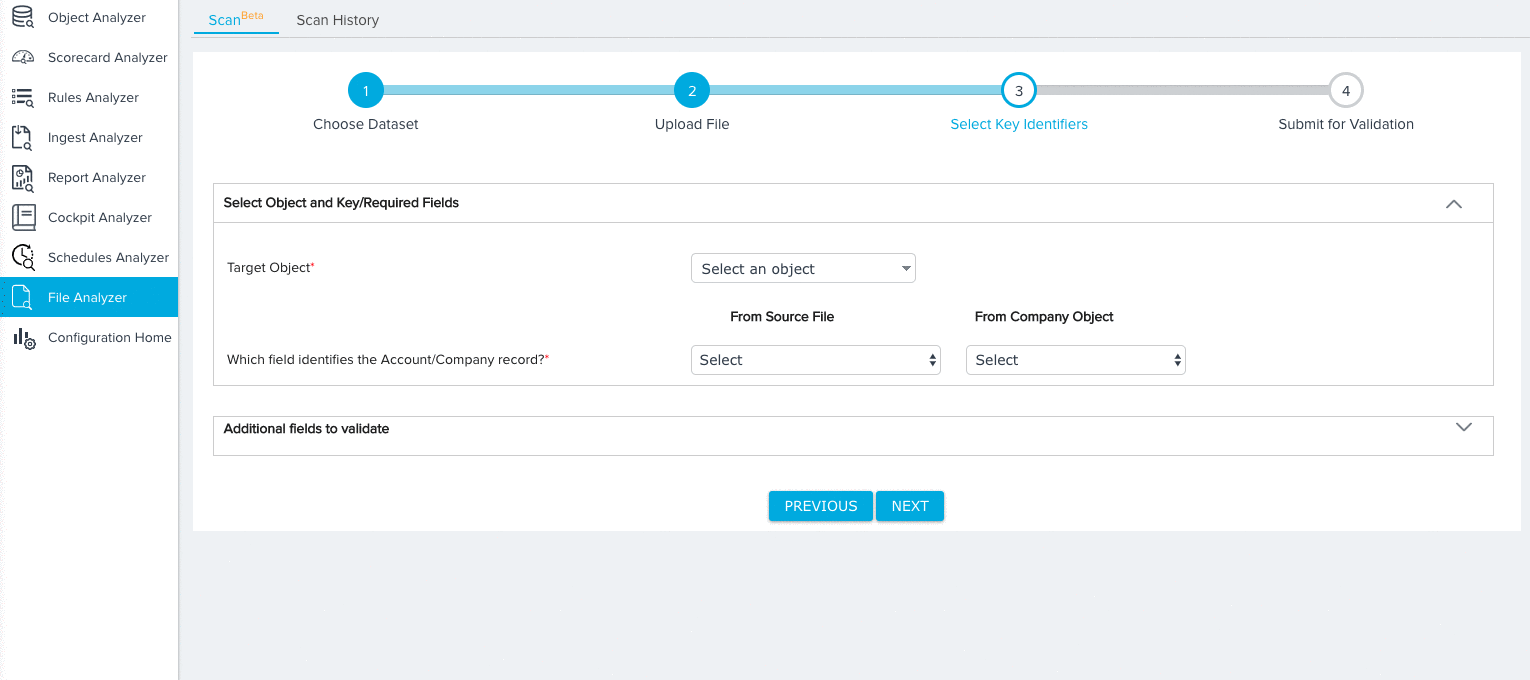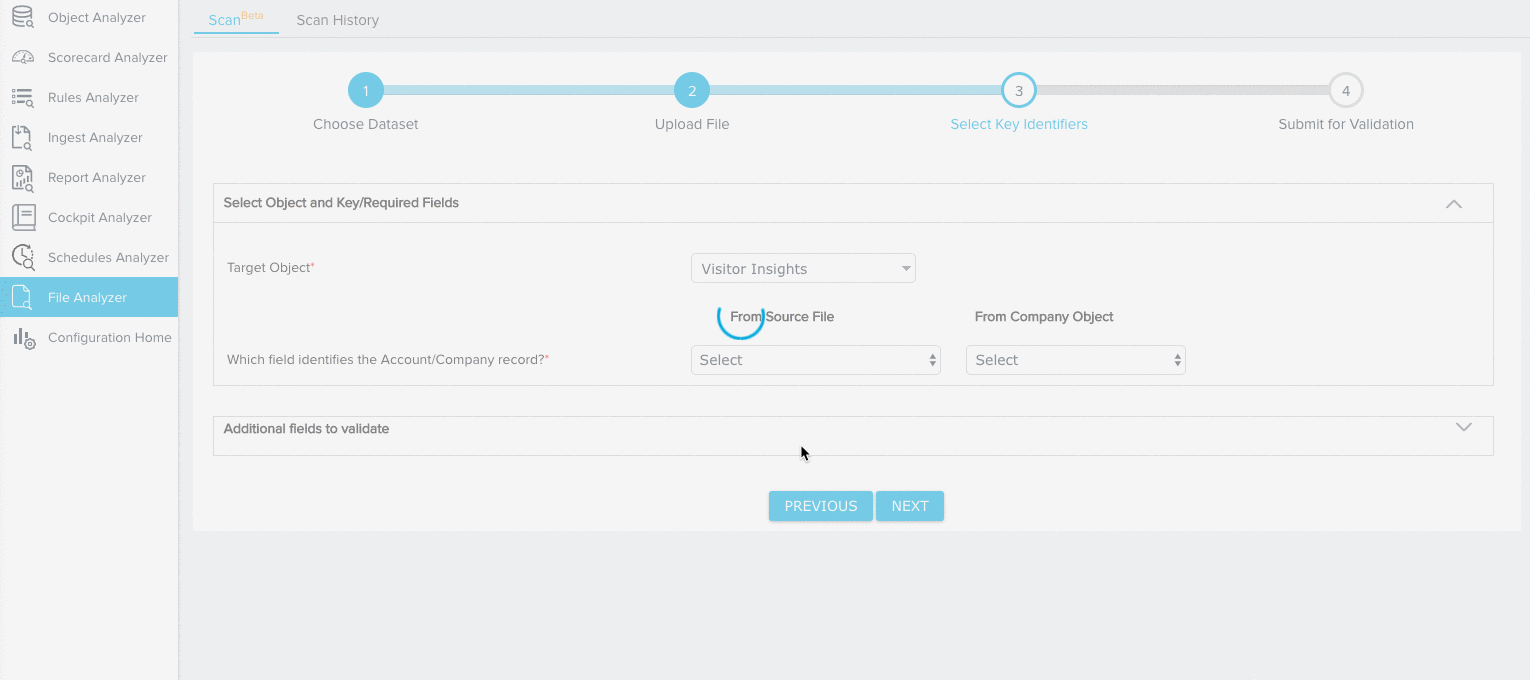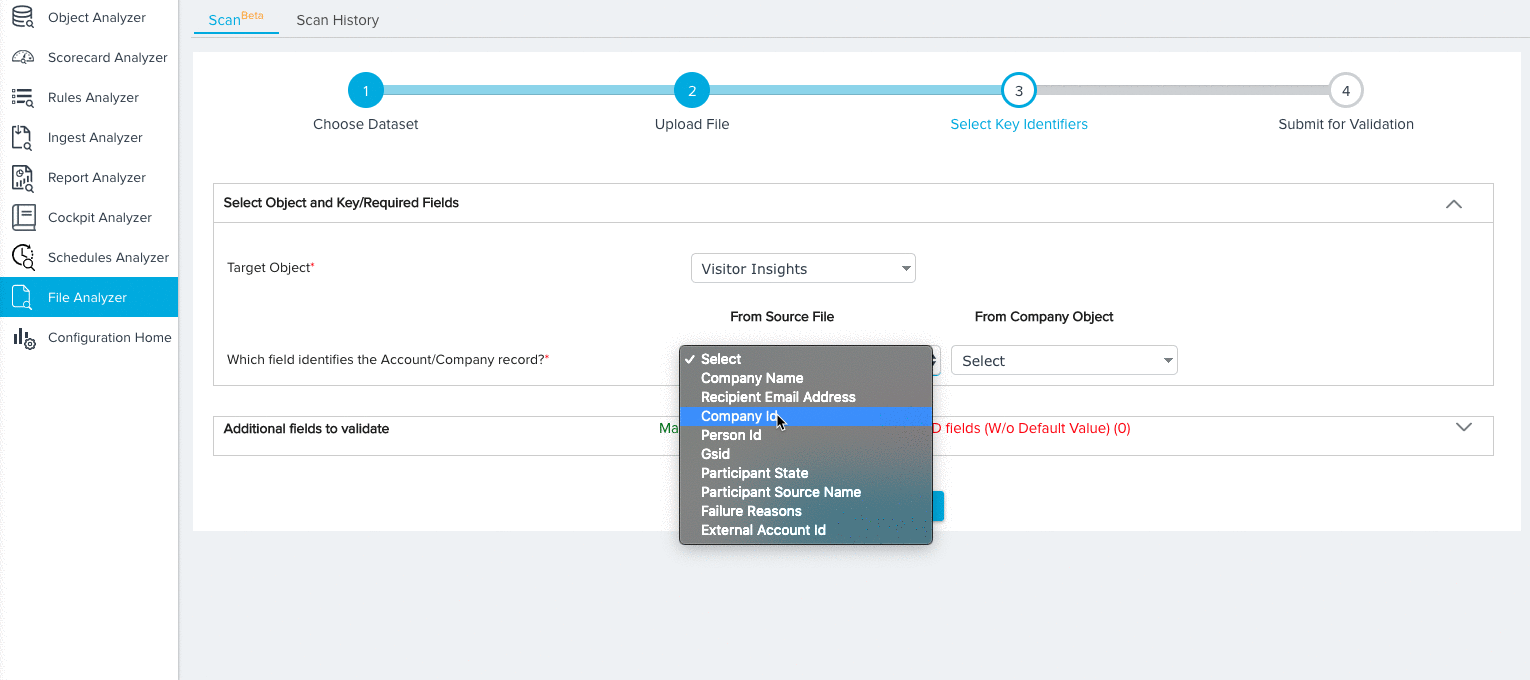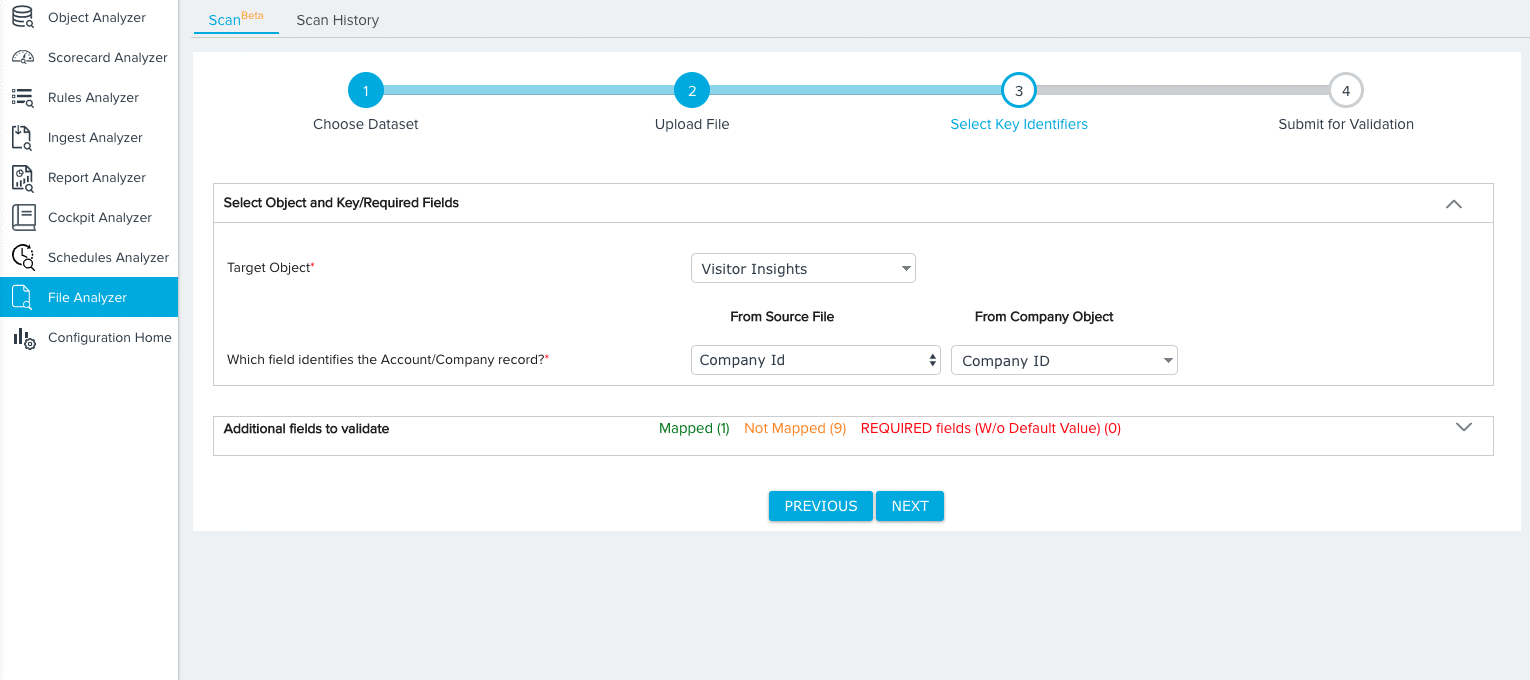
Custom Object
For the Custom Object dataset, you need to map fields from the source object to the following key identifiers:
- Target Object (Required)
- Account/Company ID (Required)
 Generic File
Generic File
For the Generic File dataset, you have the ability to select any field from the source object as a Key Identifier by checking the Key Identifier checkbox.
Scan Points
The File Analyzer scans uploaded datasets for the following scan points. Each scan point covers common potential reasons for file upload errors.
Columns count mismatch
This scan point validates if the number of columns for a record matches with the total number of headers.
Duplicate key identifiers
This scan point validates if there are any duplicate records in the key identifiers column combination.
Null values on Key Identifiers
This scan point validates if a record has null values in fields marked as key identifiers.
Duplicate rows in file
This scan point validates if there are any duplicate records.
Data type doesn’t match with the expected data type.
This scan point validates if the column data type matches with the original data type selected by the user.
Null records in required column
This scan point validates if a column marked as required has null values.
Have invalid lookup values
This scan point validates if the data in a lookup column exists in the parent object’s looked up field.
Duplicates on Name field
This scan point validates if rows have duplicate values on the “Name” field.
Scan History
The Scan History Data table contains an entry for every file scan completed within the org and displays the following fields:
- Triggered By: The user who completed the scan.
- Triggered Date: The date/time the scan was completed.
- Scan Type: The file upload method used to complete the scan.
- File Name: The name of the uploaded file.
- Result: The completion status of the file’s analysis
 You can take the following actions in the Scan History tab:
You can take the following actions in the Scan History tab:
- Refresh: Reload the table with the latest scan history data.
- View Details: Click to view the results of the scanned file analysis. For more information on scan results, refer to Scan Results.
- PROCESSING: The file is still being scanned and the results are not ready to be viewed.
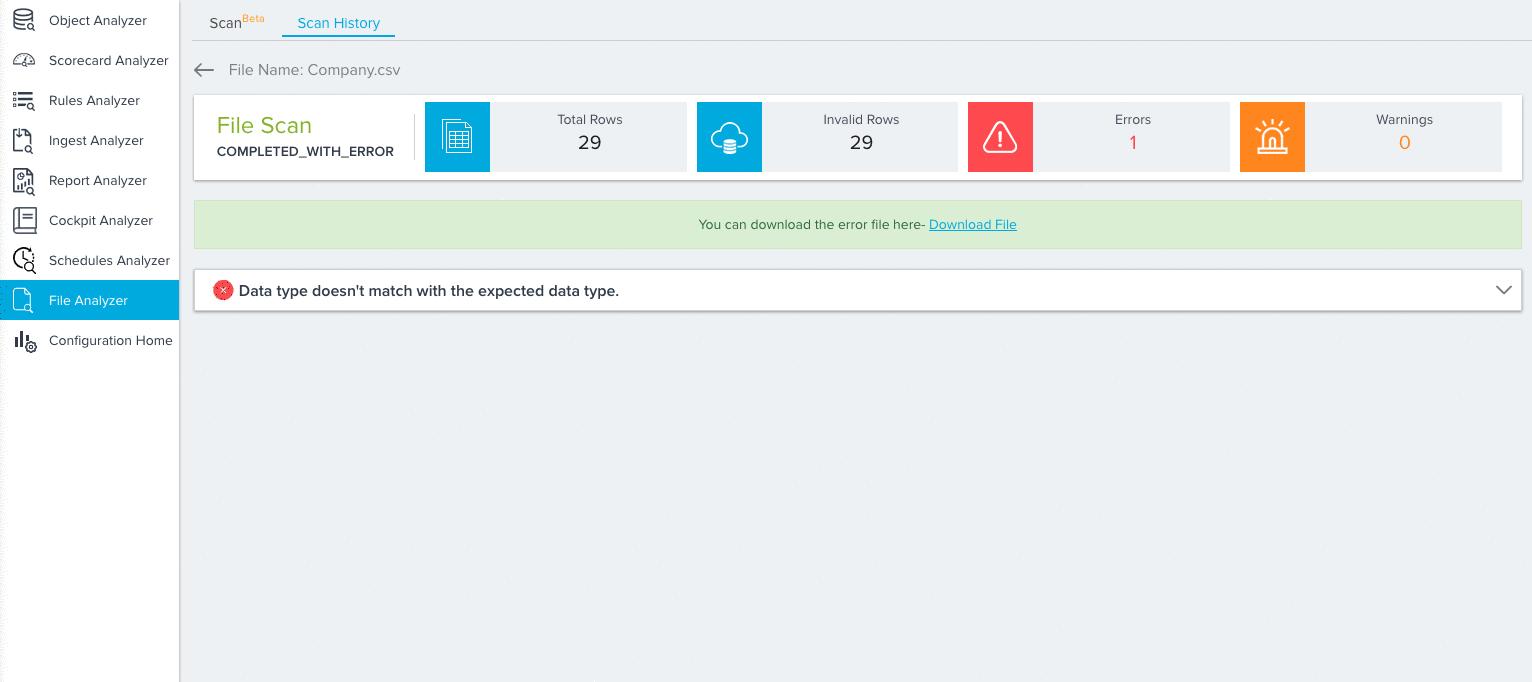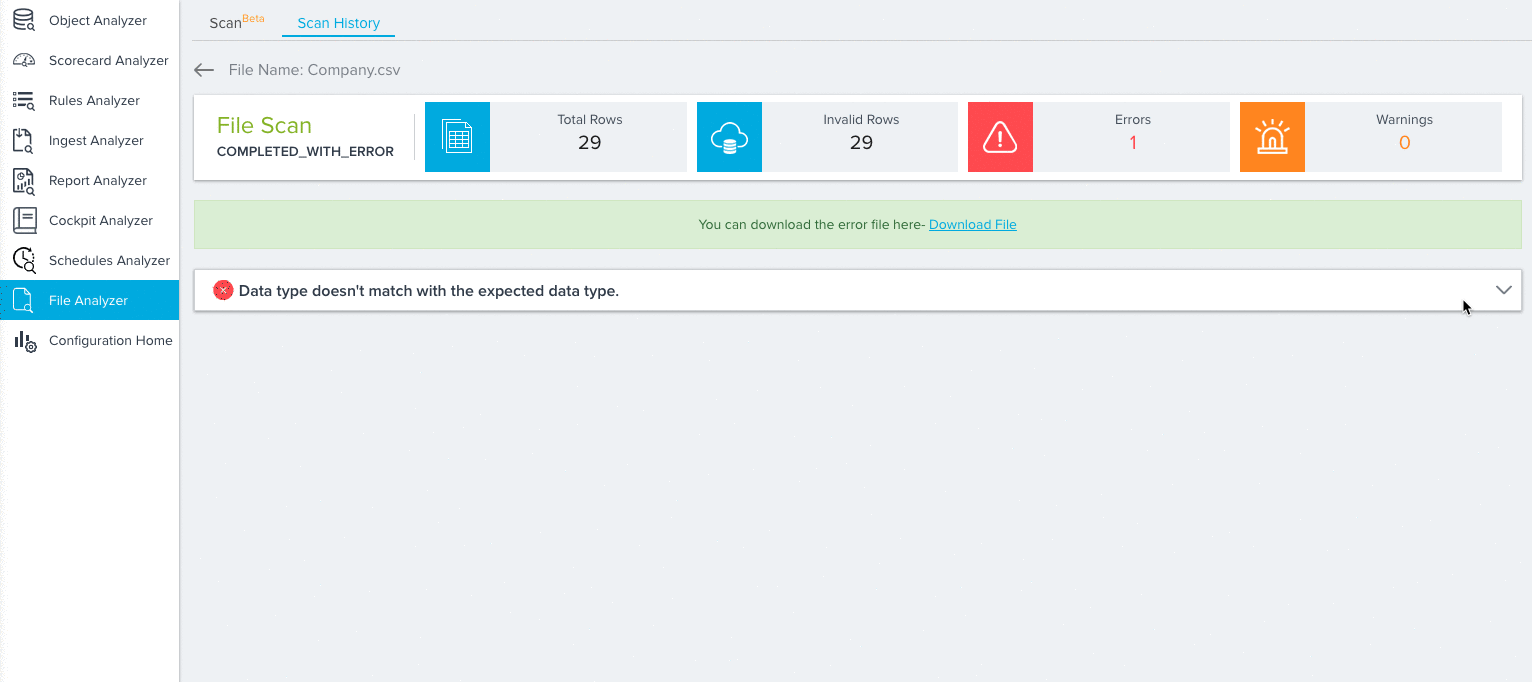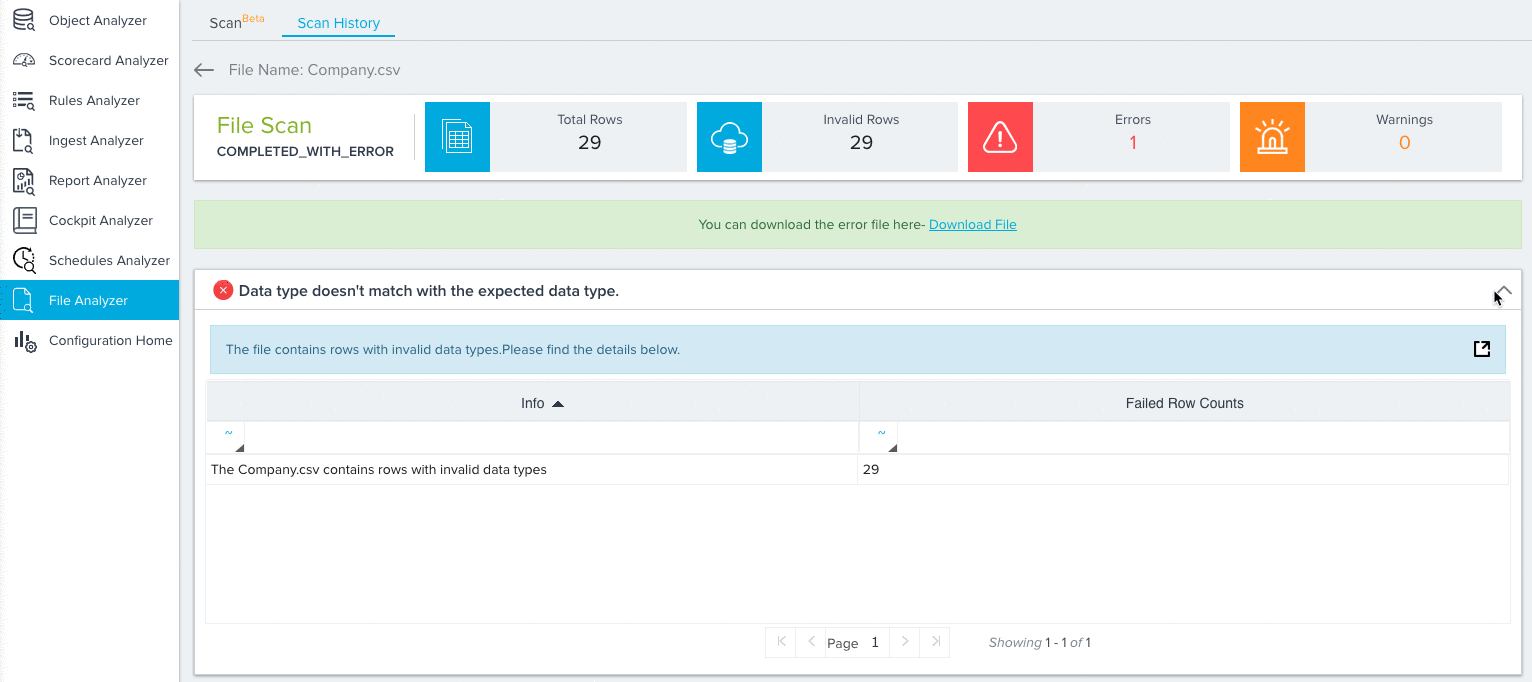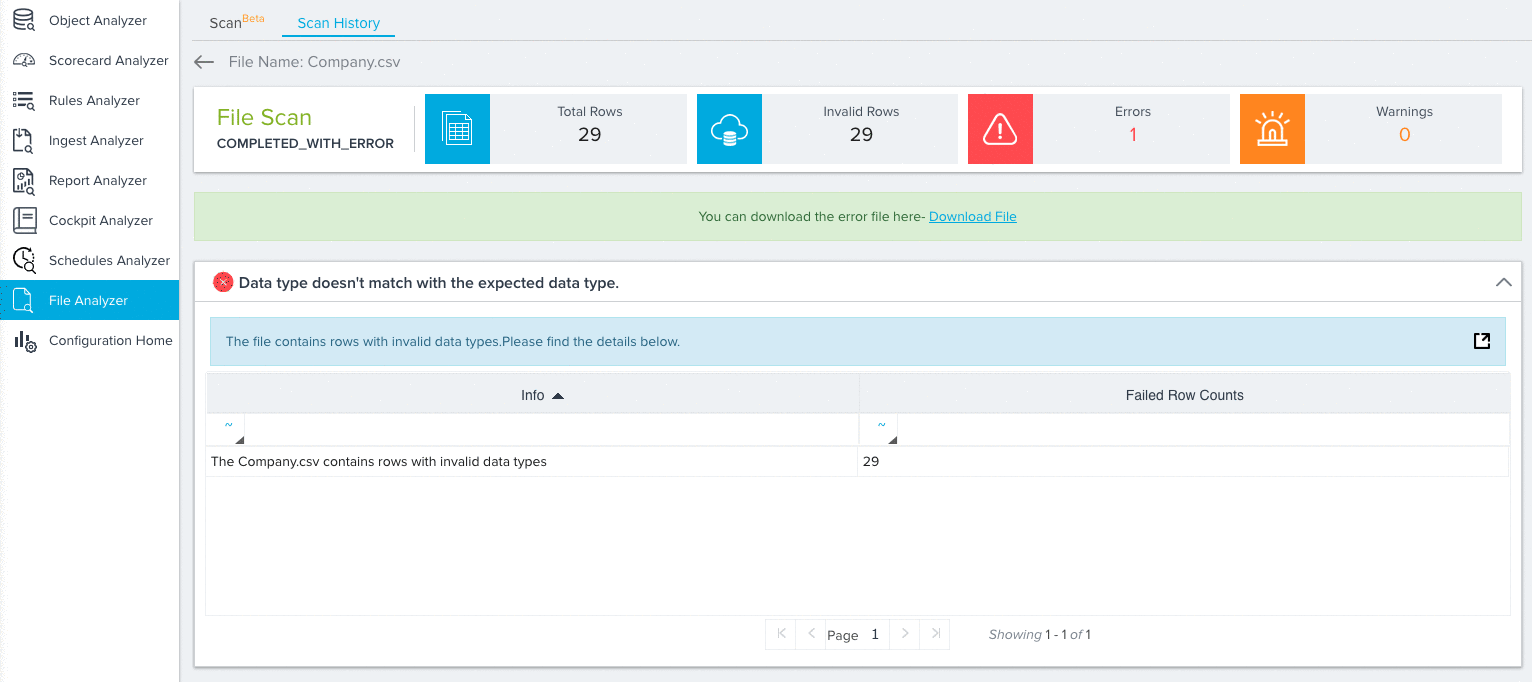
Scan Results
You can view the results of any scan completed by the File Analyzer. To view these results, navigate to the Scan History tab and click View details for the results you wish to view. This will open the scan results page.
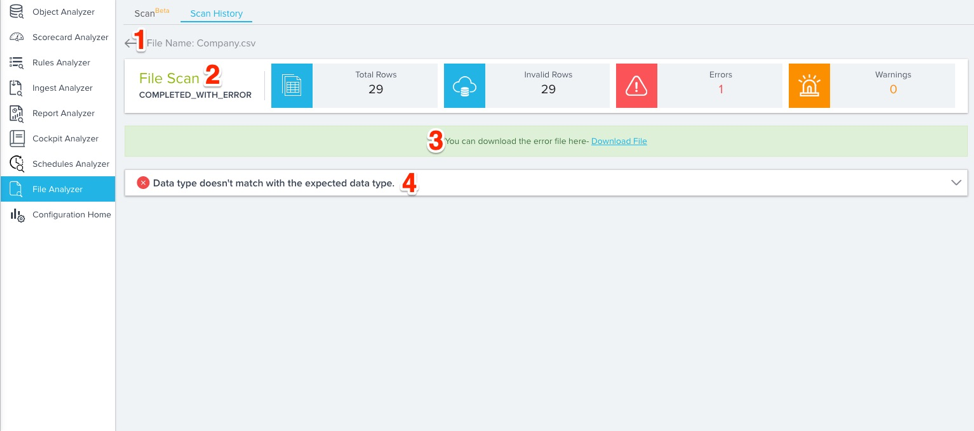
- Navigate Back: Click here to navigate back to the Scan History page.
- File Scan Dashboard: This displays a summary of the scanned file including the number of Total Rows, Invalid Rows, Errors, and Warnings.
- Download Error File: Click here to download the scan’s error file as a CSV.
- Scan Points: Each scan point the File Analyzer identified in its scan will be listed here. You can click each scan point to expand it and view more details.