S3 Dataset Task in Rules Engine
Gainsight NXT
Overview
This article provides guidelines on how Admins can create a dataset by fetching data from a csv/tsv file in any S3 bucket configured in Connectors 2.0 or Gainsight management. These csv/tsv files can be uploaded manually into the S3 bucket or exported into the S3 bucket from another Rules Engine task. This task allows Admins to compose a dataset task from a csv/tsv. Once the dataset is created, Admins can apply other tasks and set up actions on it.
For more information on export an output dataset from Rules Engine to Amazon S3 bucket, refer to Export to S3 from Rules Engine.
Following are the use cases where you can use this task:
- You can fetch data from a historical csv/tsv file in the Gainsight managed or any S3 bucket if you know the exact file name. You can then put this data in the Gainsight bucket.
- While exporting output csv/tsv files into the S3 bucket from another Rules Engine task, Admins could have configured to export a set of smaller files instead of a big file (Ex: larger than 10 GB).
For more details on the task configurations, refer to the S3 File Configuration section.
Prerequisites
The prerequisites to setup an S3 Dataset task are:
- Create an S3 connection in the Connectors 2.0 page. For more information on this configuration, refer Create an S3 Connection in Connectors 2.0.
- Before an S3 dataset is created, make sure that the source csv/tsv file is available in the S3 bucket.
- Ensure that Date and DateTime values in the csv/tsv file are in one of the formats listed in the Date Configuration section.
Creating an S3 Dataset Task
To create an S3 Dataset Task:
- Navigate to Administration > Rules Engine.
- Click Create Rule. Create Rule page appears.
- Provide the following in the Create Rule page:
- Select the Company option in the Rule For field.
- Enter Rule Name.
- Select a folder for the rule
- Enter Description [Optional].
- Click NEXT. The Setup Rule page appears.
- Click S3 DATASET TASK. S3 Dataset configuration page appears. This page has three sections, S3 File Configuration, Columns, and Date Configuration.
- Enter the Task Name, Task Description, and Output Dataset Name in the Setup Rule header.
Note: Output Dataset Name auto populates from Task Name and it can be changed to a different name. It has no dependency on the Task Name.
In this use case, the following details are used:
- Task Name: Extract from S3 [Maximum 80 characters and should be Alphanumeric; _ and space are supported]
- Task Description: Extract data from a file in the S3 bucket [Maximum 200 characters]
- Output Dataset Name: Extract from S3 [Maximum 60 characters and should be Alphanumeric; _ and space are supported]. This gets pre-populated with the task name by default.
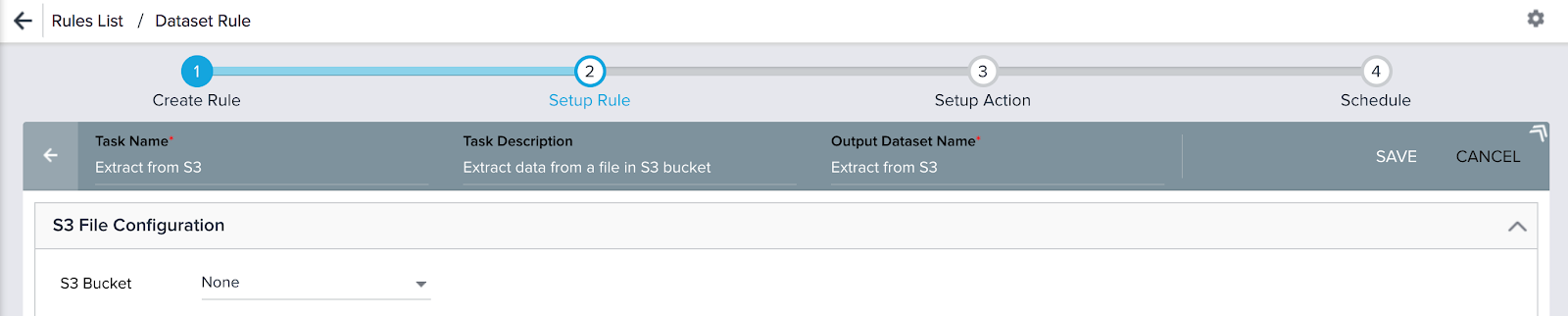
The S3 Dataset page has three sections, S3 File Configuration, Columns, and Date Configuration as shown below. Admins can configure this page to setup an S3 extract job. Depending on this configuration, columns in the csv/tsv file are extracted to fields in the S3 dataset.
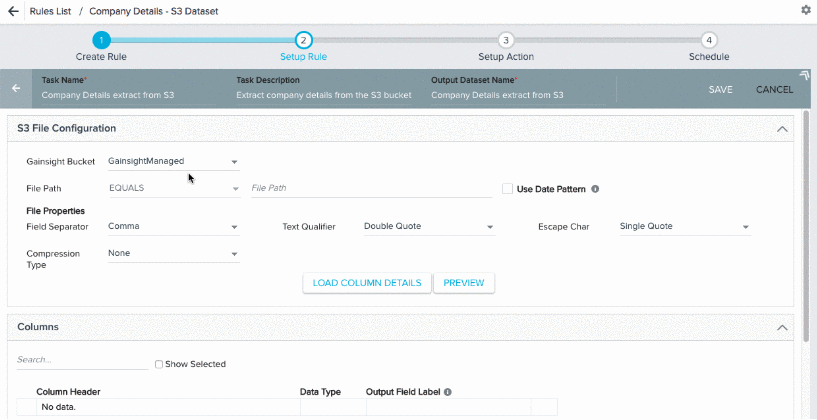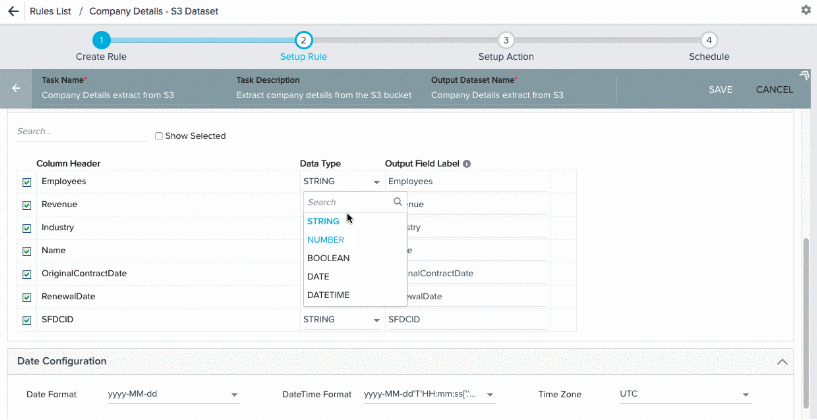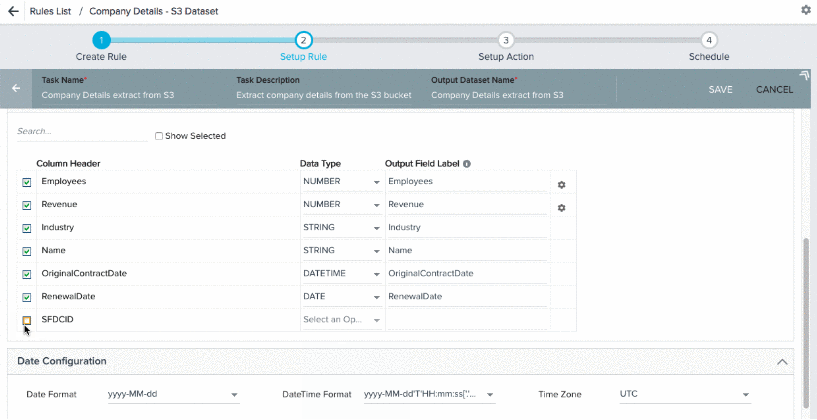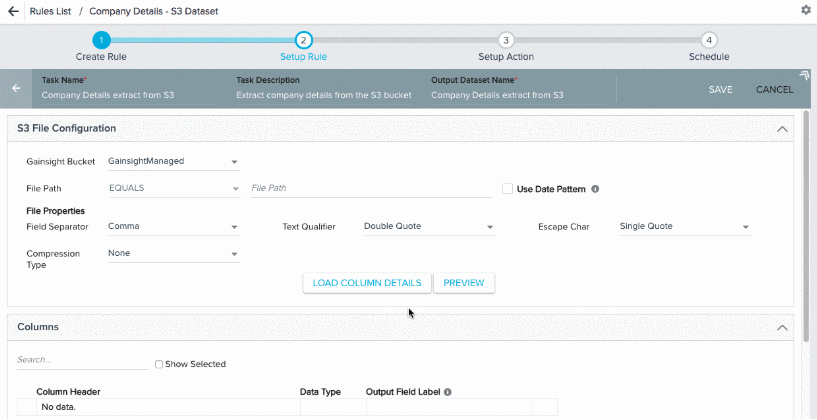
S3 File Configuration
Perform the following configurations in this section:
-
Select correct S3 bucket:
- Gainsight Managed, if you want to fetch a csv/tsv file from the Gainsight Managed bucket
- Your S3 custom bucket, if you want to fetch a csv/tsv file from your S3 custom bucket
Notes:
- You can see an S3 bucket here for which you have established an S3 connection in the Connectors 2.0 page as shown in the Prerequisites.
- CSV/TSV files having a maximum size of 1GB can be loaded.
- In the File Path field, you have the following options for the file name:
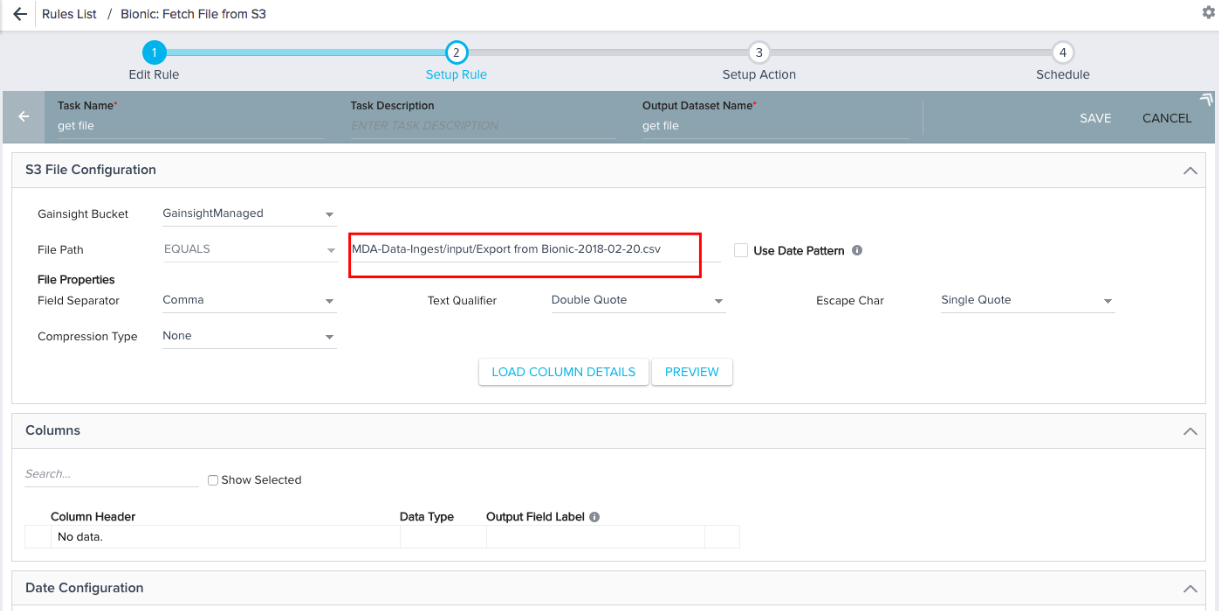
- Equals: If you know the exact file name in the S3 bucket with csv/tsv extension (Example: CompanyDetails.csv or CompanyDetails-2018-02-20.csv), use the option Equals to select that specific file for data loading into the S3 dataset. You can use this option to load an historical file from the S3 bucket. If your csv/tsv file has .gzip or .bzip as extension, select the specific Compression Type in the file properties. Select the other file properties as required for smooth data loading. However, Gainsight supports the following file properties:
- Field Separator: , (Comma) as separator for the csv files and (Tab) for the tsv files
- Text Qualifier: “ (Double Quote) or ‘ (Single Quote)
- Escape Character: \ (Backslash), ‘ (Single Quote), or “ (Double Quote)
- Compression Type: gzip or bzip
- Starts with: You can use this option only when you select the Use Date Pattern checkbox. This option can be used in combination with Date Pattern in the file name. If you enter the partial file name with date pattern, the specific file is selected for creating S3 dataset. You should select the file properties like Field Separator and Compression Type to select the correct file from the S3 bucket. You can use this option if you want to ingest data from multiple files of similar file names into the S3 Dataset. While exporting output csv/tsv files into the S3 bucket from another Rule task, if the file size is big (Ex: larger than 10 GB), Admins can configure to divide this big file into a set of smaller files with similar file names (Ex: file 1 of 1.5 GB, file 2 of 2 GB, etc.) and export into the S3 bucket. These smaller files have the same columns and the records are divided into multiple files. While creating an S3 Dataset using the option Starts with, records from all of the smaller files are fetched into the S3 dataset.
- Use Date Pattern: Enable this to use Date Pattern in the file path. If you select this, ${pattern} appears in the file name and it can be placed anywhere in the file path. Enter the number of days to subtract from the rule date in the ${pattern} formula. Date pattern in the file name can be applied with both the Equals and Starts with options in the File Path field.
Note: Position of the Date Pattern in the file name should correspond with the name of the files exported to the S3 bucket. -
You can use the following combination of File Path and Date Pattern options for the mentioned use cases:
File Path: In all the below conditions, make sure that you enter full file path from S3 bucket. For example, if a file named "S3partial - Sheet1.csv" was placed in the folder /input/ of a given S3 Bucket, and if you use the option Equals, the file path would be MDA-Data-Ingest/input/S3partial - Sheet1.csv.- Equals: You can use this option only if you know the exact file name (with/without file generated date) in the S3 bucket with csv/tsv extension (Example: S3partial - Sheet1.csv or S3partial - Sheet1-2018-02-20.csv). The file path would be S3partial - Sheet1.csv. However, if the file would have been placed in a folder called input, the file path would have been input/S3partial - Sheet1.csv.
- Equals + Date Pattern: You can use this option if you know the file name without the file generated date. You can add Date Pattern to select a specific file for data ingestion. For example, if the Rule execution date is 2018-02-24 and you want to ingest data from a file exported to S3 bucket on 2018-02-20. You can subtract 4 days from Rule Date. The file name will be S3partial - Sheet1-${pattern}.csv where ${pattern} = Subtract 4 days from Rule Date with format yyyy-MM-dd and the file path will be input/S3partial - Sheet1-${pattern}.csv.
- Starts with + Date Pattern: You can use this option if you know the file name partially without file generated date. You can add Date Pattern to select a file or a set of files that match the file path for data ingestion. For example, if the Rule execution date is 2018-02-24 and if you want to ingest data from a file or multiple files that match the file path exported to S3 bucket on 2018-02-20. You can subtract 4 days from the Rule Date. The file name will be S3partial - Sheet1 -${pattern} where ${pattern} = Subtract 4 days from Rule Date with format yyyy-MM-dd and the file path will be input/ S3partial - Sheet1 -${pattern}.
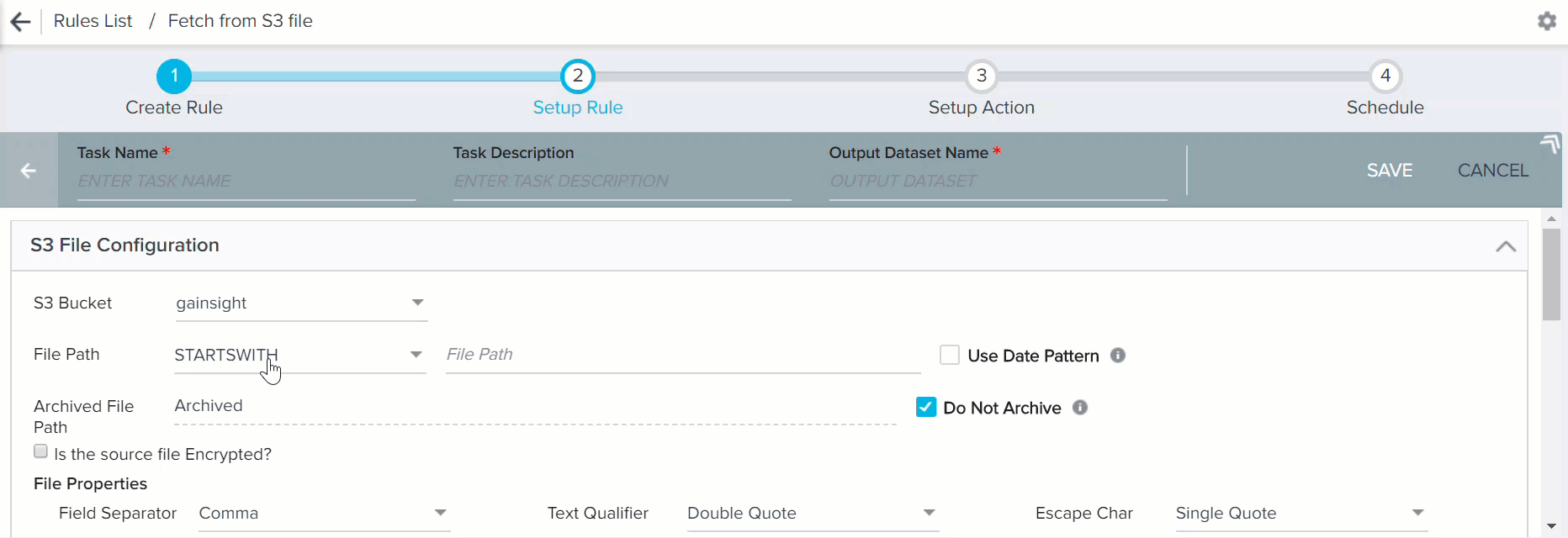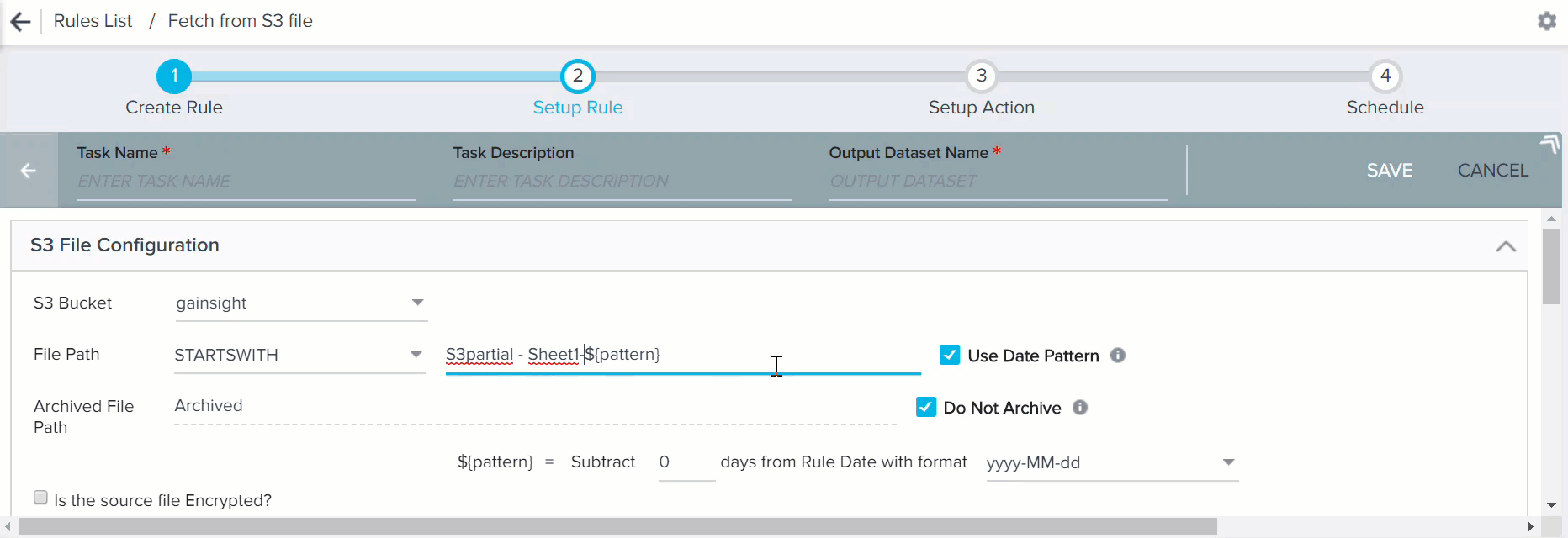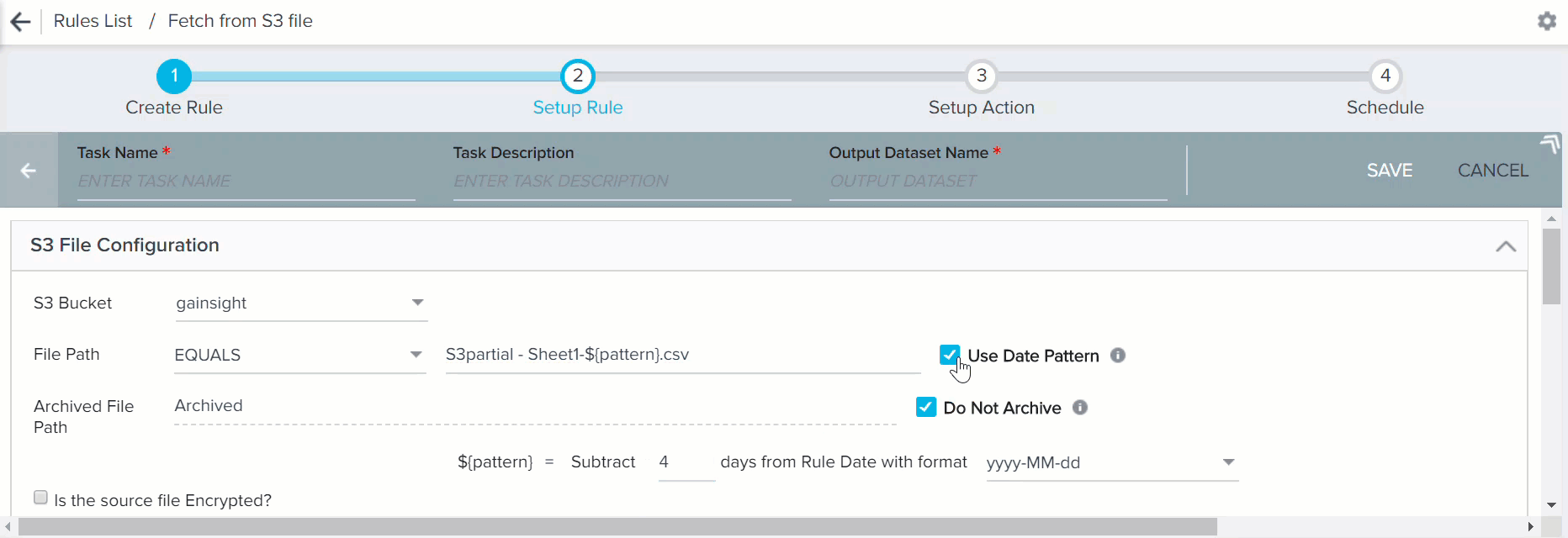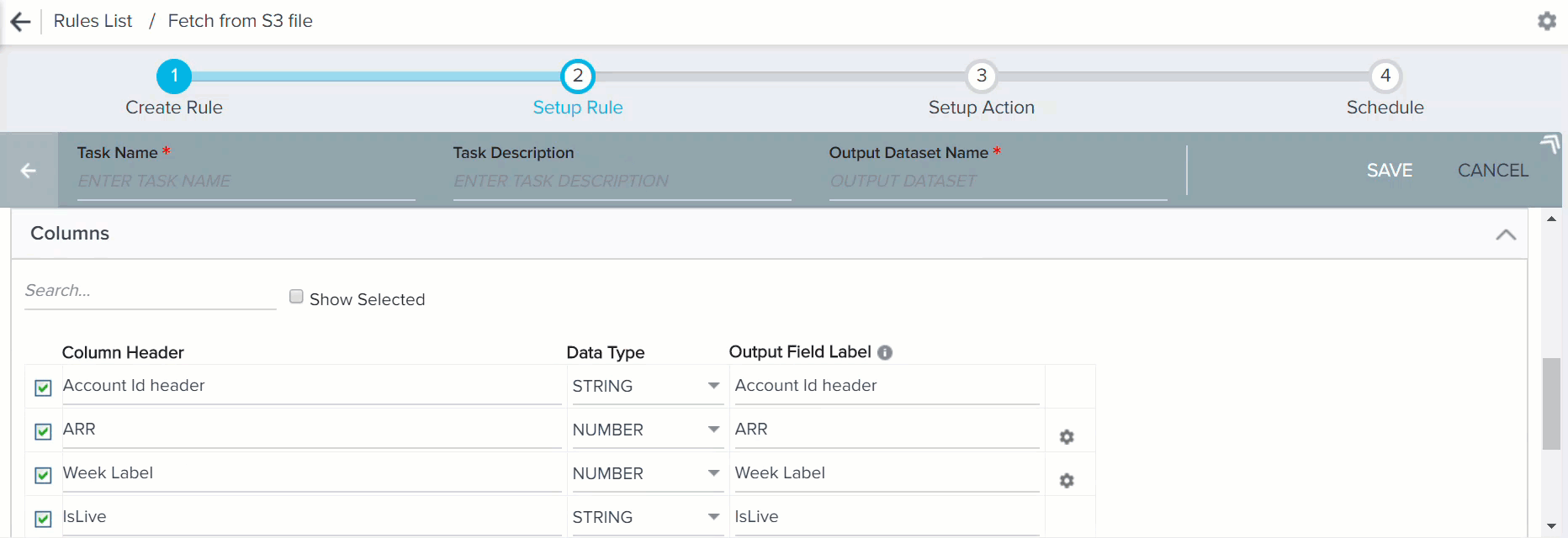
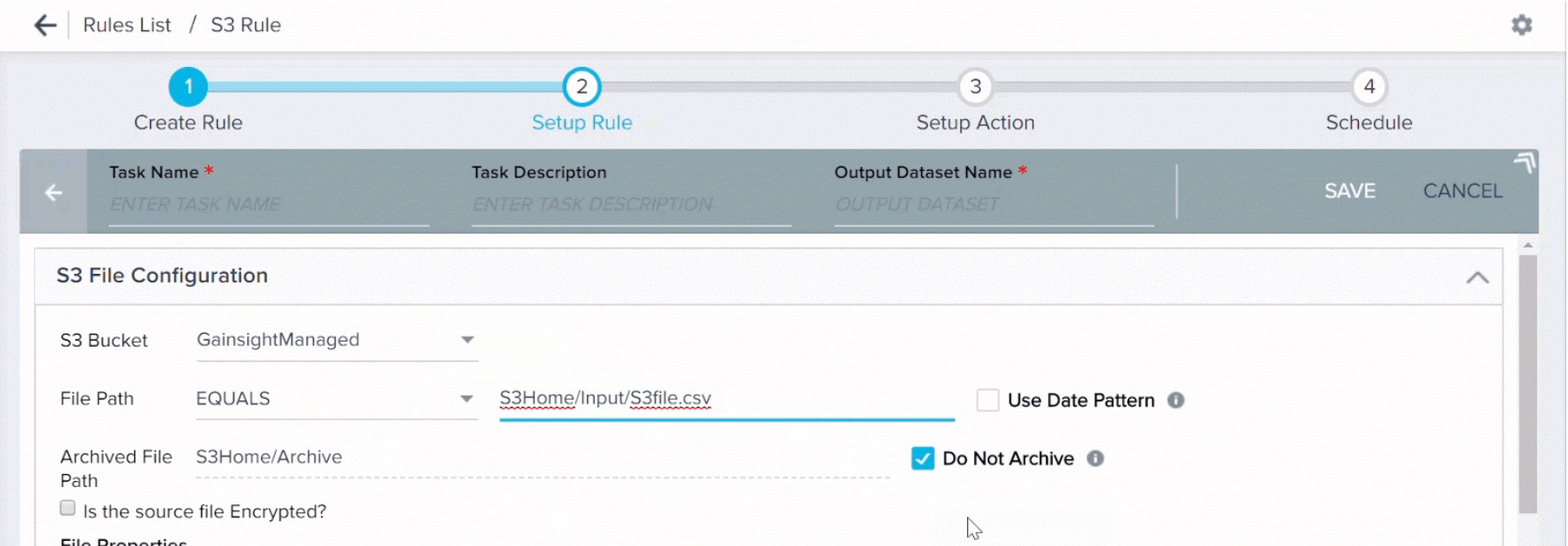
Clear the Do Not Archive check box to archive the S3 file after use. By default, this check box is selected. When you clear this check box, used files are automatically moved to an archive folder. You must specify a path for the archived folder. A new folder is created in the specified path.
.jpg?revision=1)
By default, the archived folder is created at the same level at which the source file is located. For example, if your source CSV file is located immediately in the S3 bucket and not nested in any folder, the archived folder is created at the immediate level in S3 bucket. If your source CSV file is nested in a folder, the archived folder is also created at the nested level. You can modify the default path, if required.
IMPORTANT:
-
By default, the Do Not Archive check box is selected. You must clear the check box to archive files.
-
For a custom bucket, Gainsight must have the required permissions to create a folder in your S3 bucket. If Gainsight does not have the required permissions, the rule is executed but the archive folder is not created.
- When you select the option Equals, make sure to add the extensions .csv/.tsv and .bzip/.gz for the file format (Comma separated/Tab separated) and compression type respectively.
- When you select the option Equals, make sure to add the extensions .csv/.tsv and .bzip/.gz for the file format (Comma separated/Tab separated) and compression type respectively.
- Is the source file Encrypted: If your csv file in the S3 bucket is encrypted, select the checkbox and correct PGP key to apply decryption on the csv/tsv file.
Note: To configure a PGP key for decryption with Gainsight, contact support@gainsight.com so that you can use the same here.
- When you select the option Equals or Starts with, make sure to select the following File Properties as required:
- Field Separator: Comma / Tab for the .csv/.tsv files respectively
- Compression Type: bzip / gzip for the file compression types respectively. Select None if the compression is not applied on the source file in the S3 bucket.
If you do not apply the above configurations correctly or you have provided incorrect S3 bucket details while creating an S3 connection in the Connectors 2.0 page, the Rule execution fails.
Notes:
- Field Separator: Use , (Comma) as separator for the csv files and (Tab) for the tsv files.
- Text Qualifier: It is used to import a value (along with special characters) specified in the Quotation while importing data. It is recommended to use the same Text Qualifier in the S3 file configuration which is used in the csv/tsv file to upload. By default, Double Quote is selected in the S3 file configuration, but users can change to Single Quote as required.
- Escape character: It is used to include special character in the value and it is placed before special character in the value. It is recommended to use Backslash in the csv/tsv file to avoid any data discrepancy in the S3 Dataset.
- Compression Type: Use .bzip or .gzip as required.
- When all the configurations are completed in this section, click PREVIEW. This fetches the first 10 records from the source file and displays them in the Preview Results window.
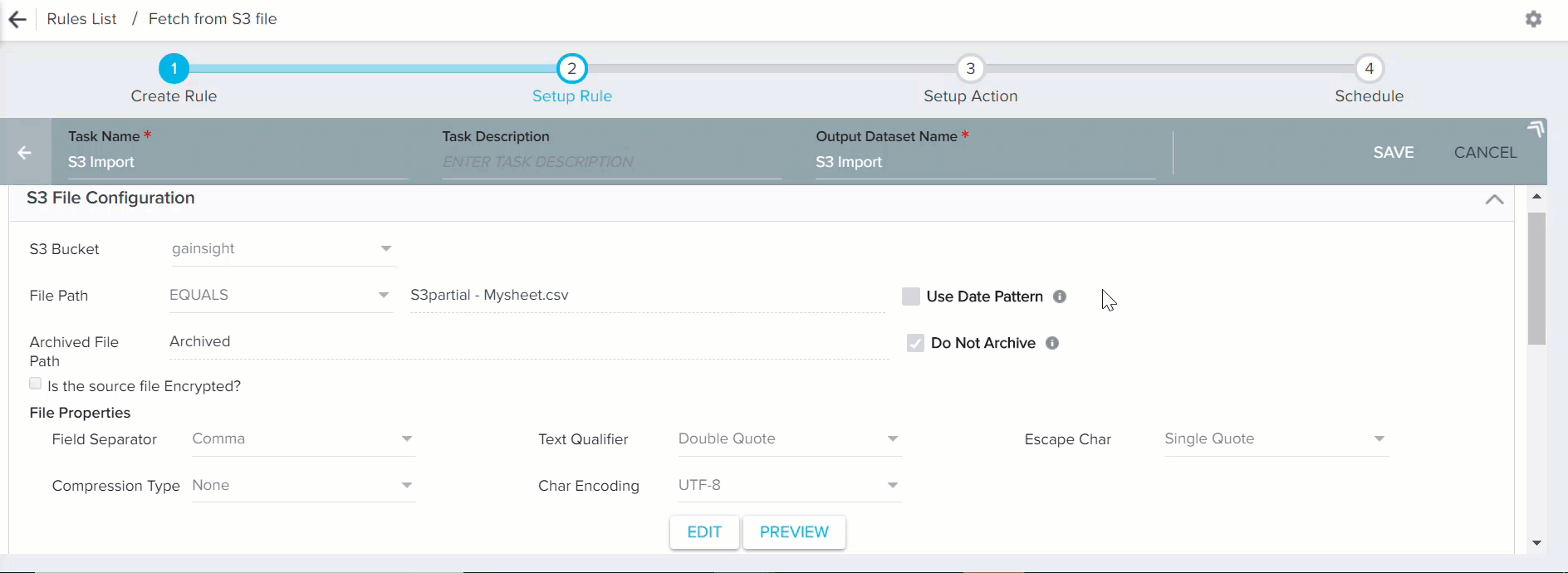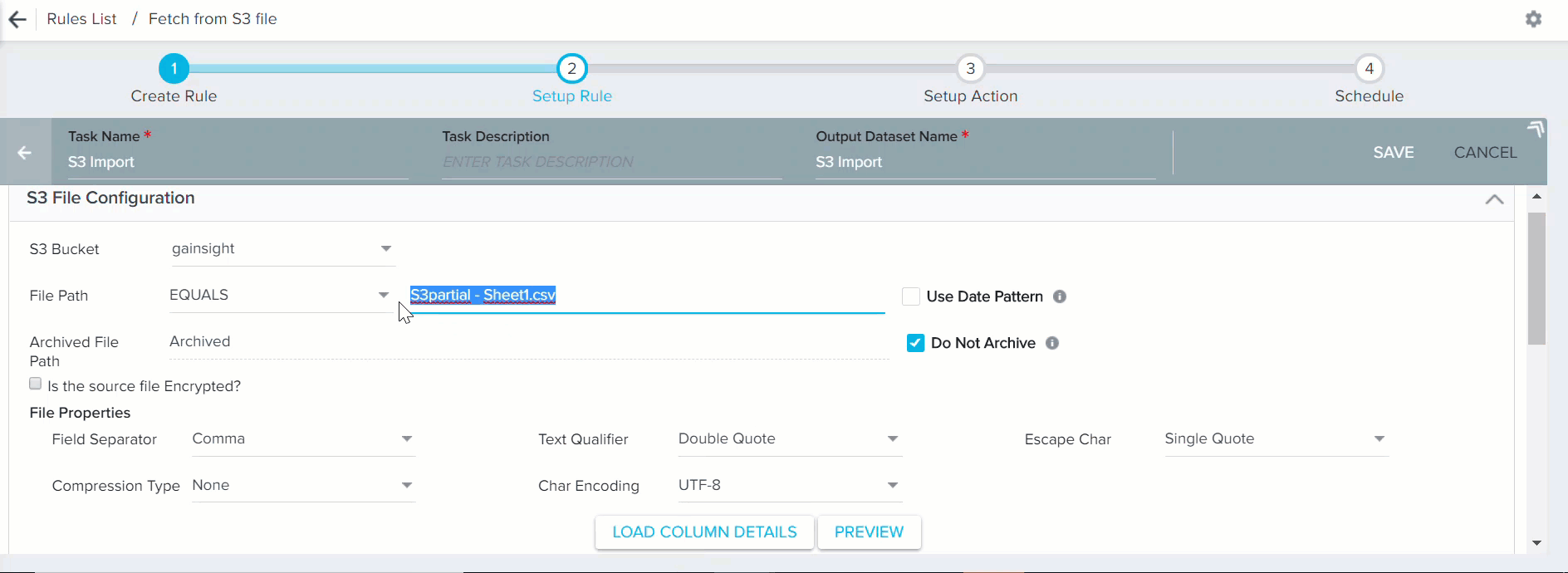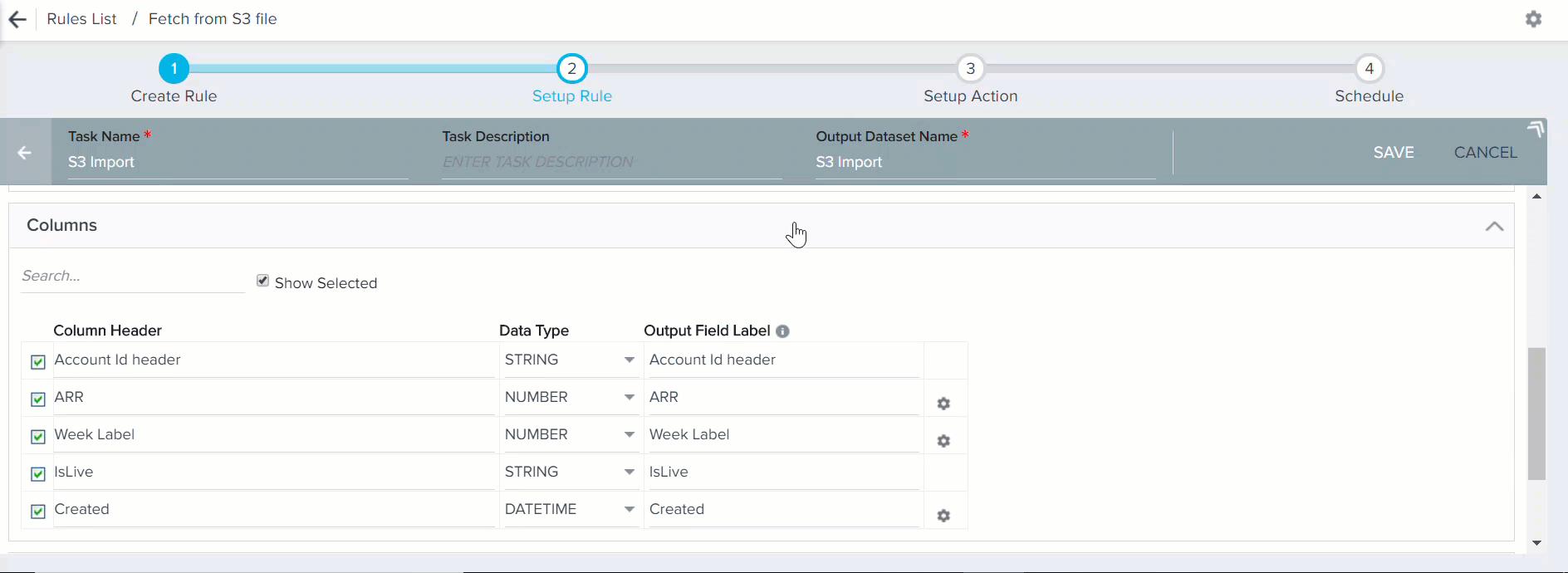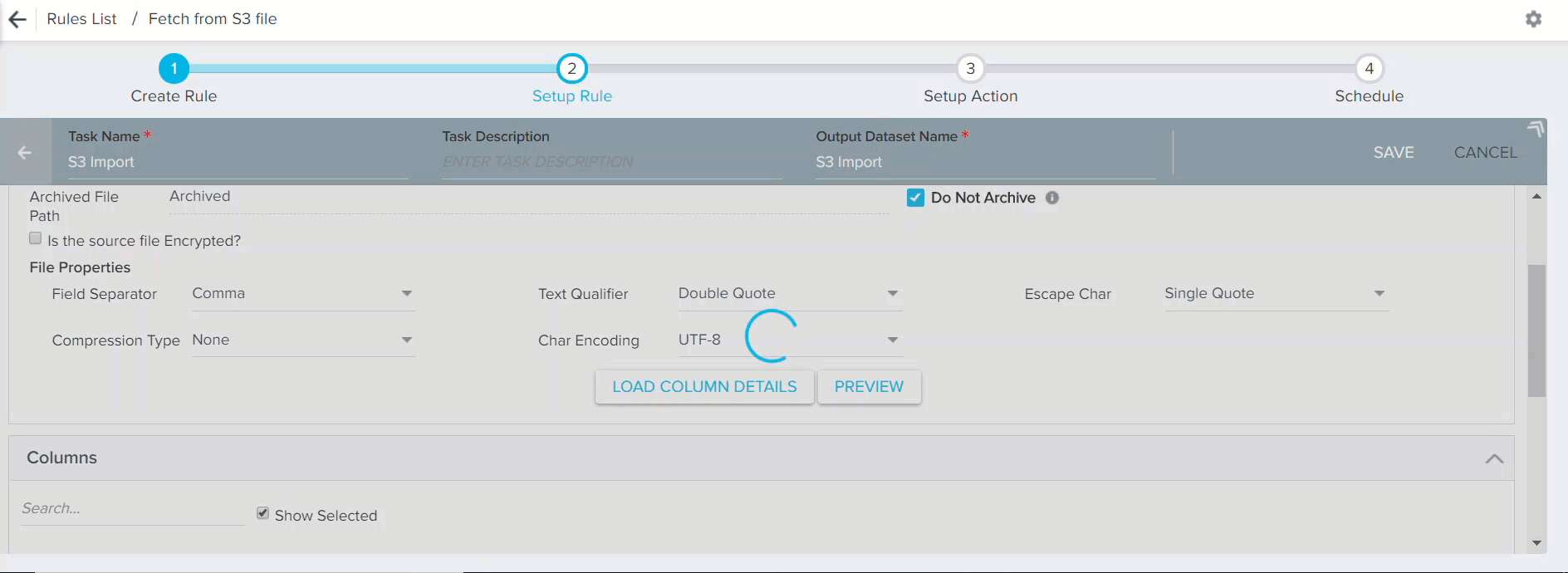
- Click LOAD COLUMN DETAILS. The Columns section appears as shown in the section below.
Columns
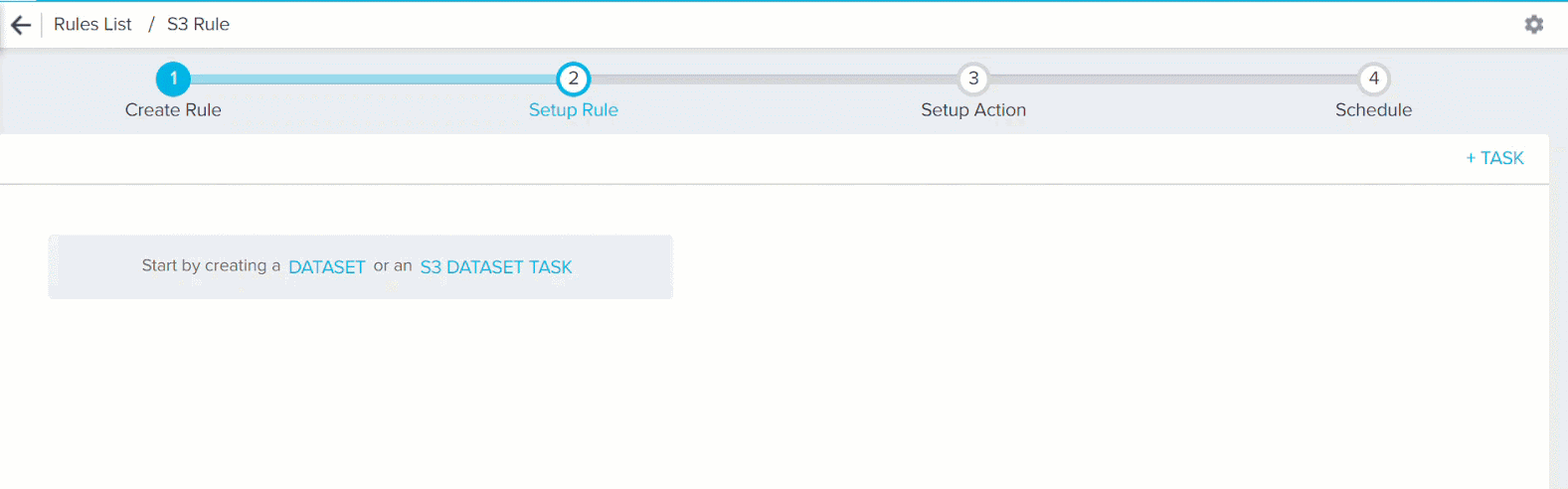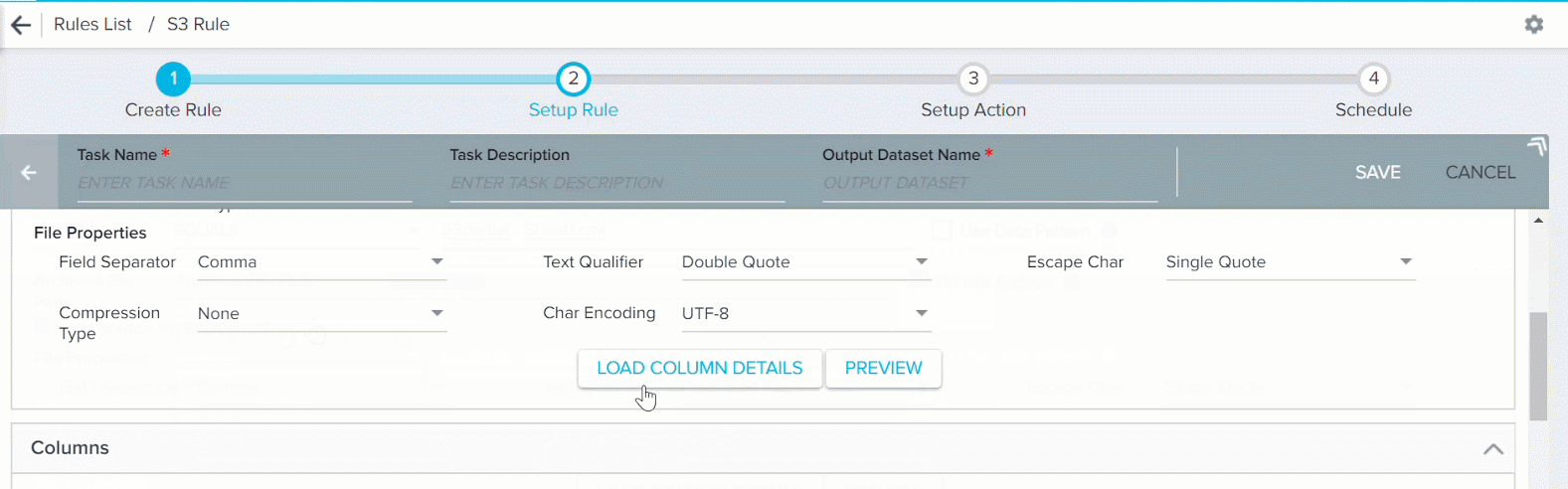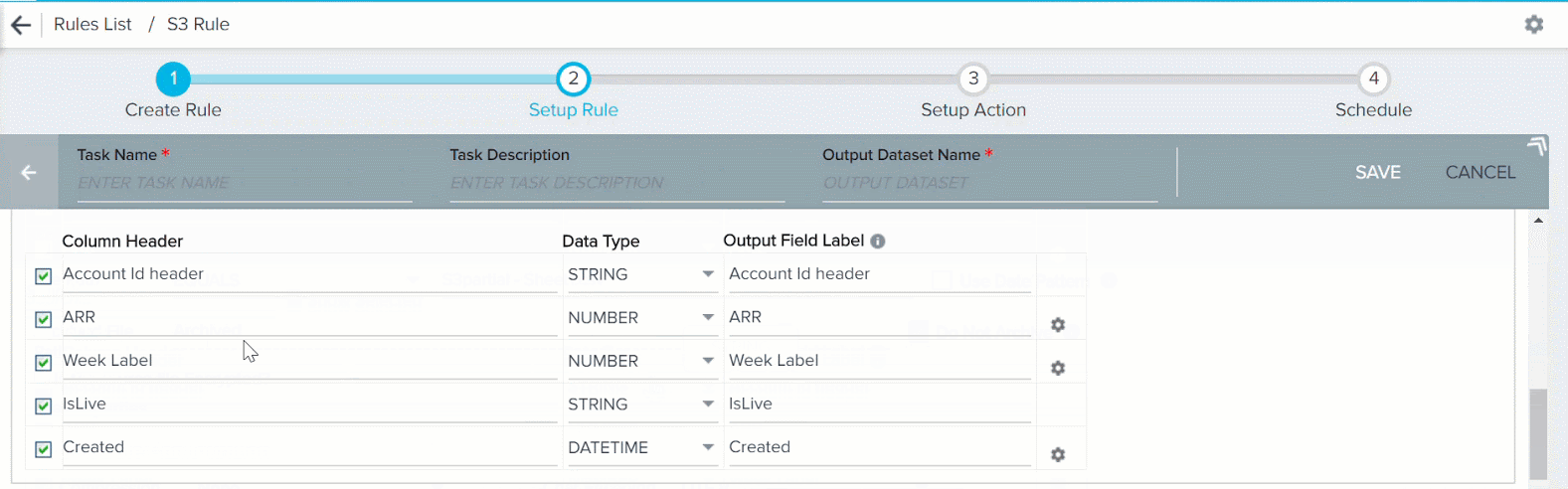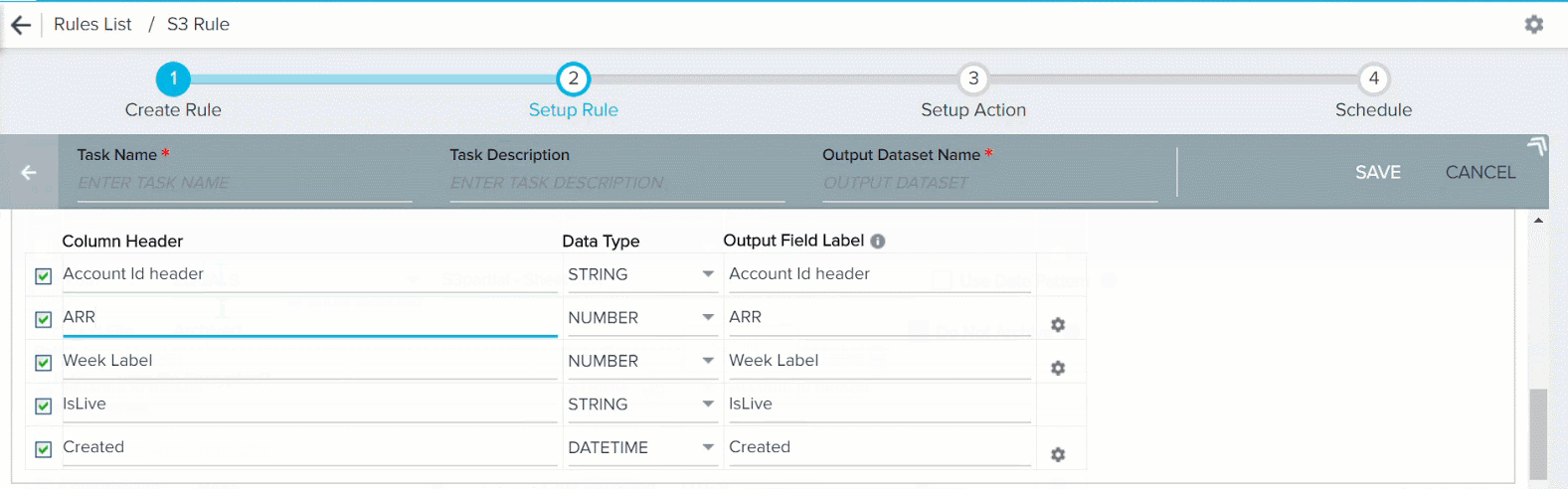
When you click LOAD COLUMN DETAILS in the S3 File Configuration section, following columns appear:
- Column Header: Column headers that are fetched from csv/tsv file in the S3 bucket.
- Data Type: The Date Type is selected automatically for each column header. However, you can modify this field and change the default Data Type for the required column headers. Ensure that the Data Types of Column Header and its corresponding Output Field Label are same. Gainsight supports six Data Types:
- Boolean: This Data Type can hold either a True/False value.
- Date: This Data Type can hold Date values.
- DateTime: This Data Type can hold Date and Time values.
- Number: This Data Type can hold integers and floating point values.
- String: This Data Type can hold characters and String values.
- GSID: This Data Type can hold values of the GSID type. GSID is a 36 digit unique ID assigned to every record in Gainsight.
Example of GSID: You can export records from an S3 Dataset. The exported records can have fields like Company ID which is a GSID field. When you import the same records through an S3 dataset, Company ID field can be automatically mapped as GSID.
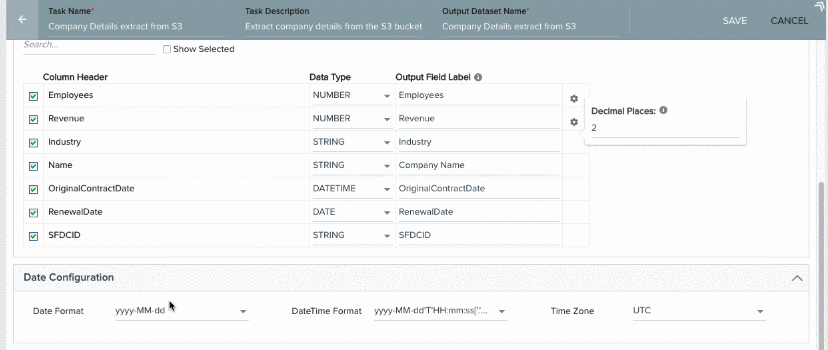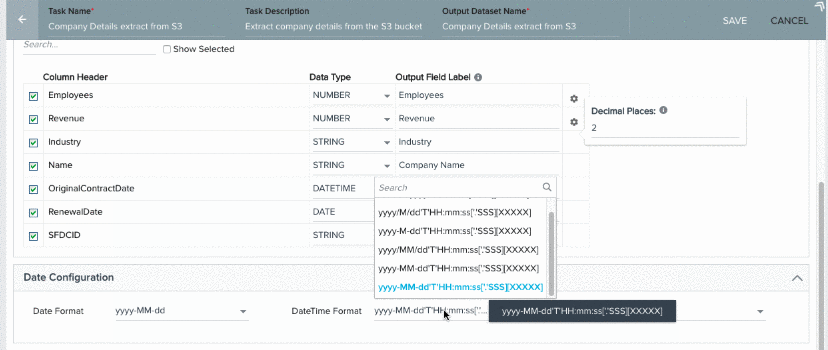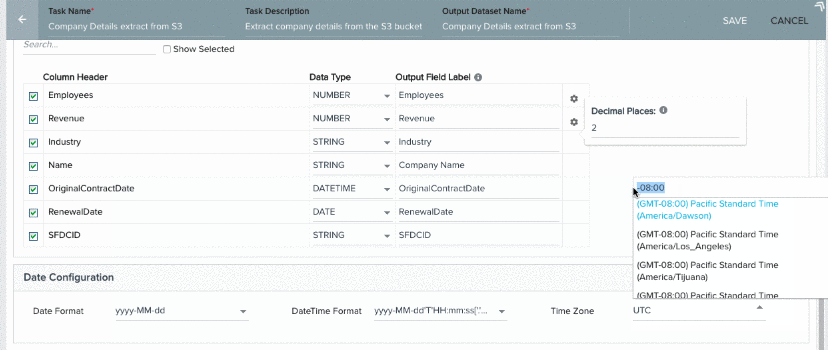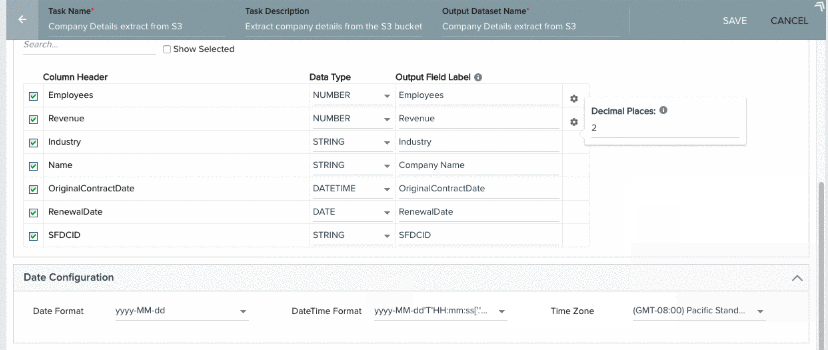
When you select Date and Date Time data types for a Column header, a settings icon is displayed. You can use this icon to set a Date or date time format only for that Column header.
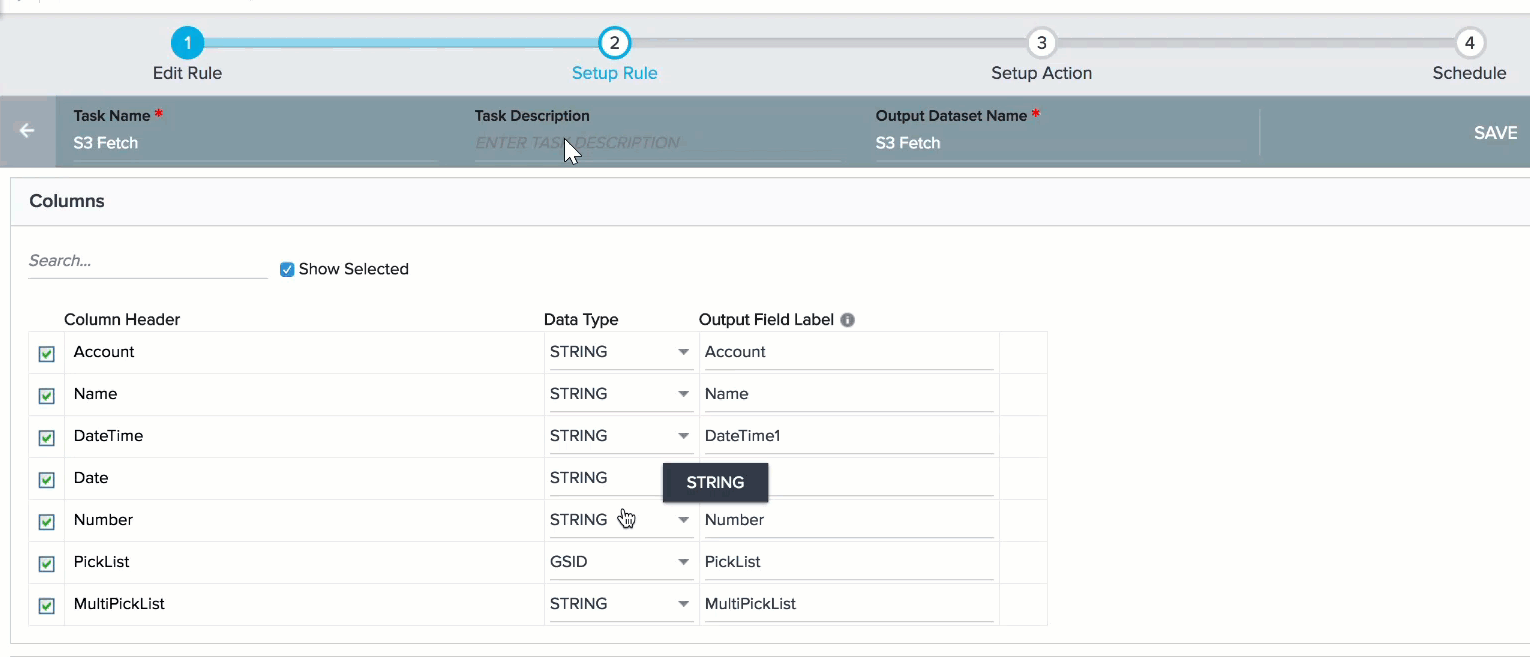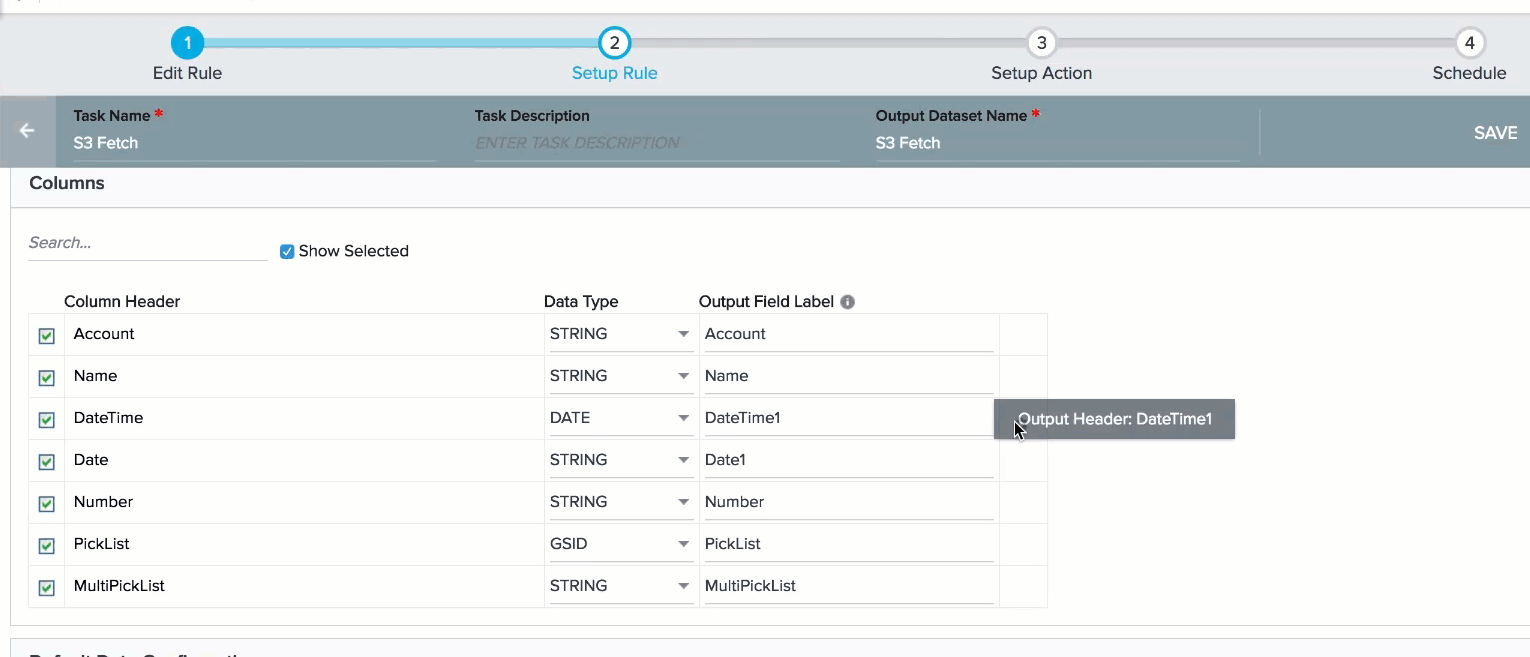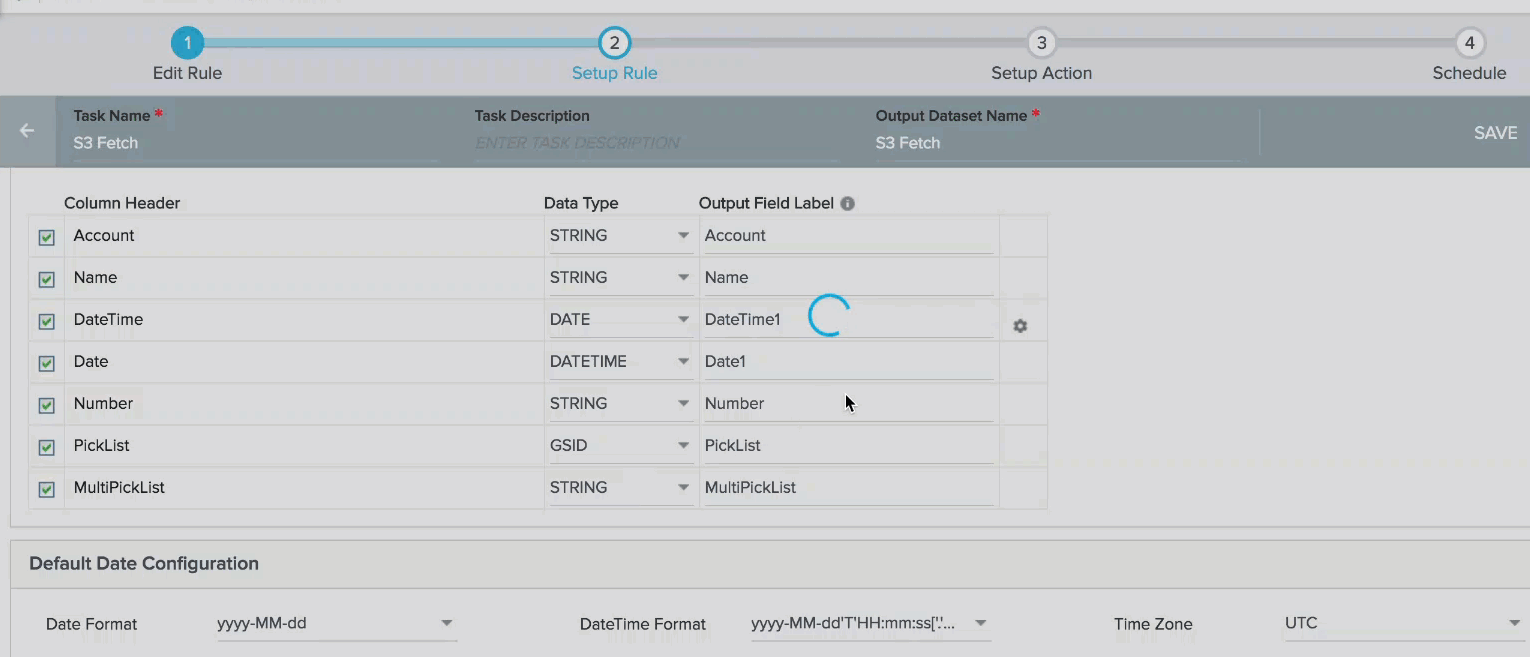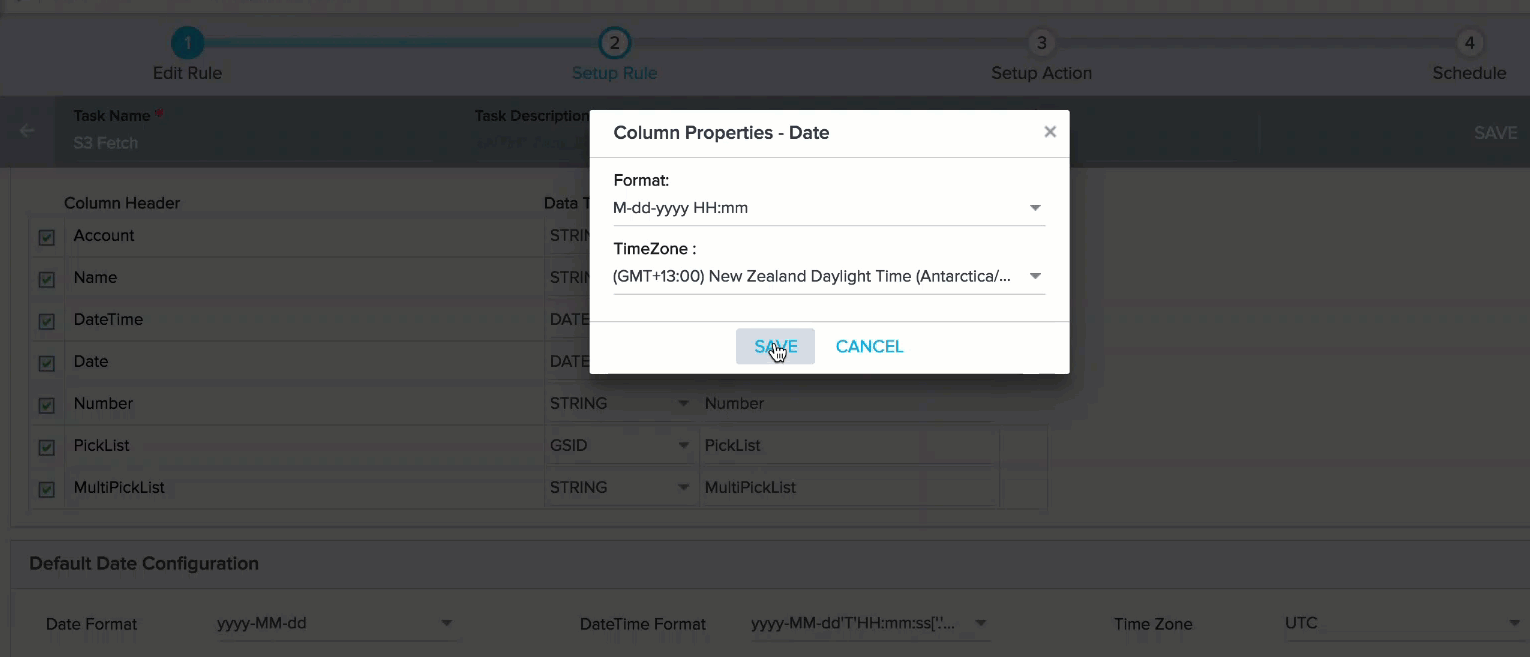
Note: If you do not select a format for Date, DateTime fields or Timezone, the format or Time Zone specified in the Default Date Configuration section is selected.
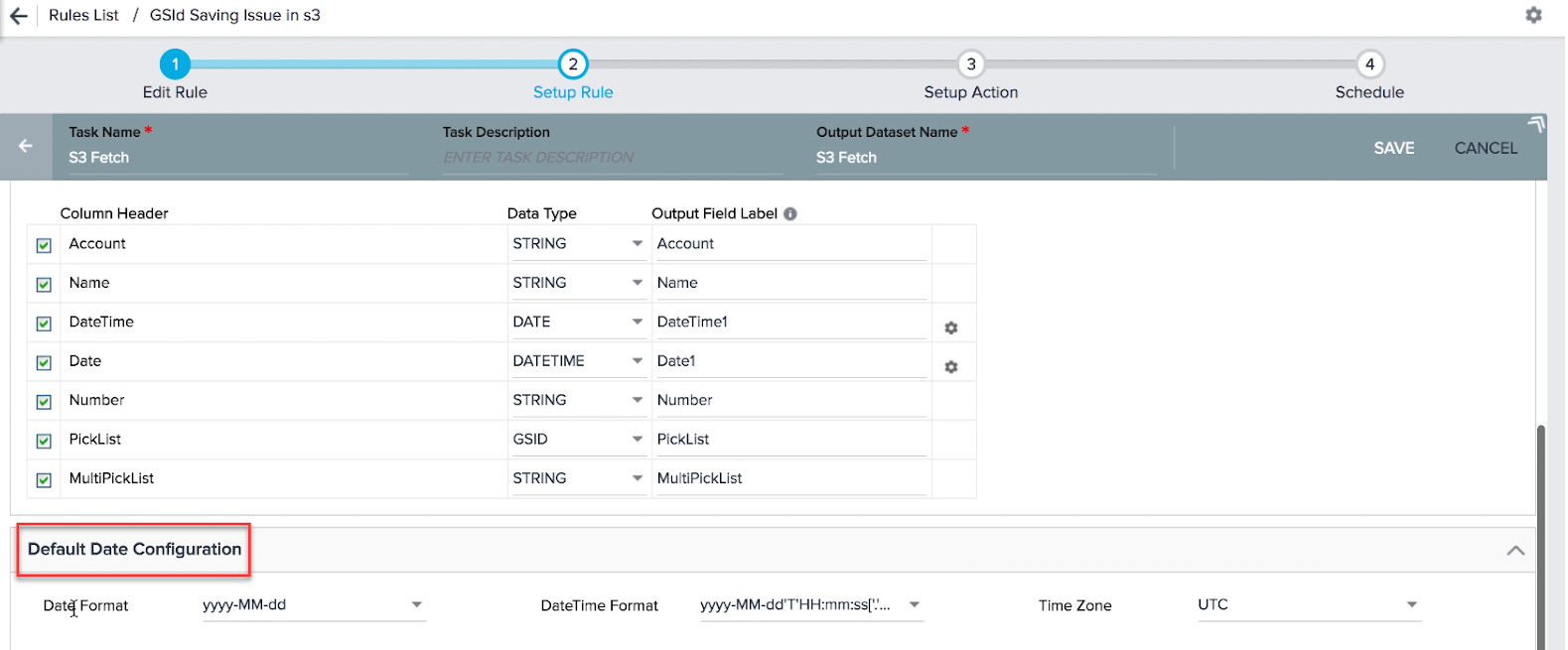
- Output Field Label: You can assign a field label in the S3 dataset into which values from csv/tsv file are fetched. You can assign the number of decimals for the Number values.
If you have dropdown list items in either labels (Ex: Active, Inactive, etc.) or their corresponding GSIDs in a CSV header, system allows you to store these values in the columns of an S3 dataset. You can use these values to match with dropdown list items in MDA (Ex: Company > Status) in the action types: Load to Gainsight objects.
If there are many fields for ingestion, you can search and select the required fields from the Search box. You can select or remove the source file column headers using the checkbox next to the Column Header name. You can do this when the source file in the S3 bucket is updated (column headers are removed).
Note: You can edit the name of the Column Headers fetched from the csv/tsv file. After you change the name of the column header in the S3 dataset, be sure to make the corresponding update in the source file, located in the S3 bucket. During rule execution, if a column has a different name in the S3 dataset and S3 bucket, the rule execution fails.
Limitations
Following of the data type mappings between CSV column headers and S3 dataset fields fail:
- String to Number
- DateTime to Date
- Date to DateTime
- String to Boolean: If value in the CSV column is not True, it loads the value as False in the S3 Dataset field.
Date Configuration
There are three configurations Date, DateTime, and Timezone available in this section. Select these formats for the records to be ingested as similar to the Date, DateTime, and Timezone formats in the csv/tsv file records in the S3 bucket. To check formats of the source csv/tsv file records, view Preview dialog in the S3 File Configuration section. Following are the use cases for these configurations:
Date Format
Select yyyy-MM-dd if the format of the date values in the source file is 2018-02-18. Following are the date formats supported in the S3 dataset task from a csv/tsv file.
- Supported formats (click here to expand the list)
-
Date Formats Example dd-MMM-yy 06-APR-21 dd-MMM-yyyy 06-APR-2021 dd/MM/yy 06/04/21 dd/MM/yyyy 06/04/2021 EEEE, dd MMMM yyyy Tuesday, 06 April 2021 M-d-yyyy 4-6-2021 M-dd-yy 4-06-21 M/d/yy 4/6/21 M/d/yyyy 4/6/2021 M/dd/yy 4/06/21 M/dd/yyyy 4/06/2021 MM-dd-yyyy 04-06-2021 MM/dd/yyyy 04/06/2021 MMMM d, yyyy April 6, 2021 yyyy-M-d 2021-4-6 yyyy-MM-dd 2021-04-06 yyyy/M/d 2021/4/6 yyyyMMdd 20210406 yyyy/MM/dd 2021/04/06 M-dd-yyyy 4-06-2021 MM-d-yyyy 04-6-2021 MM/d/yyyy 04/6/2021 MM-d-yy 04-6-21 MM/d/yy 04/6/21 M-d-yy 4-6-21
DateTime Format
Select yyyy-MM-dd’T’HH:mm:ss[‘.’SSS][XXXXX] if the format of the datetime values in the source file is 2017-03-22T12:37:23-08:00. Following are the DateTime formats supported in the S3 dataset task from a csv/tsv file.
- Supported formats (click here to expand the list)
-
Date-Time Formats Example dd/MM/yyyy hh:mm:ss['.'SSS][XXXXX] a 06/04/2021 05:06:07.000+01:00 yyyy/M/dd'T'HH:mm:ss['.'SSS][XXXXX] 2021/4/06T05:06:07.000+01:00 yyyy-M-dd'T'HH:mm:ss['.'SSS][XXXXX] 2021-4-06T05:06:07.000+01:00 yyyy/MM/dd'T'HH:mm:ss['.'SSS][XXXXX] 2021/04/06T05:06:07.000+01:00 yyyy-MM-dd'T'HH:mm:ss['.'SSS][XXXXX] 2021-04-06T05:06:07.000+01:00 M-d-yy HH:mm 4-6-21 09:25 M-d-yyyy HH:mm 4-6-2021 09:25 M-dd-yy HH:mm 4-06-21 09:25 M-dd-yyyy HH:mm 4-06-2021 09:25 M/d/yy HH:mm 4/6/21 09:25 M/d/yyyy HH:mm 4/6/2021 09:25 M/dd/yy HH:mm 4/06/21 09:25 M/dd/yyyy HH:mm 4/06/2021 09:25 MM-d-yy HH:mm 04-6-21 09:25 MM-d-yyyy HH:mm 04-6-2021 09:25 MM-dd-yy HH:mm 04-06-21 09:25 MM-dd-yyyy HH:mm 04-06-2021 09:25 MM-dd-yyyy HH:mm:ss 04-06-2021 09:25:57 MM/d/yy HH:mm 04/6/21 09:25 MM/d/yyyy HH:mm 04/6/2021 09:25 MM/dd/yy HH:mm 04/06/21 09:25 MM/dd/yyyy HH:mm 04/06/2021 09:25 MM/dd/yyyy HH:mm:ss 04/06/2021 09:25:57 yyyy-MM-dd HH:mm:ss 2021-04-06 08:00:00 yyyy-MM-dd HH:mm:ss.SSS 2021-04-06 08:00:00.000 yyyy-MM-dd HH:mm:ssZ 2021-04-06 5:06:07 +0100 yyyy-MM-dd'T'HH:mm:ss.SSS'Z' 2021-04-06T05:06:07.000Z yyyy-MM-dd'T'HH:mm:ss.SSSZ 2021-04-06T09:07:21.205-07:00 yyyy-MM-dd'T'HH:mm:ss.SSS 2021-04-06T05:06:07.206 yyyy-MM-dd'T'HH:mm:ssz 2021-04-06T09:07:21-07:00 yyyy-MM-dd'T'HH:mm:ssZ 2016-04-06T09:07:21.20-07:00 yyyy-MM-dd:HH-mm-ss 2021-04-06:09-24-55
Time Zone
By default, UTC time zone selected in this field. If the datetime value (Ex: 2017-03-22T12:37:23-08:00) in the source file has a time zone (Ex: -08:00), select the same time zone (GMT-08:00) Pacific Standard Time (America/Los_Angeles) in this field. If the datetime values in the source file do not have any timezone, select UTC in this field.
Data loading into the S3 dataset fails if the Date and DateTime formats selected in the Date Configuration section is not the same as in the source.
Once you set up configurations in the above three sections, click SAVE in the Setup Rule header to save the S3 dataset successfully.
Once the S3 dataset is saved, you cannot make any changes in the configurations. You can only remove the column headers after the dataset is saved. You can do this when the source file in the S3 bucket is updated (column headers are removed).
If you have feedback or questions on this feature, please share them on community.gainsight.com.
Edit S3 File Configuration
You can also edit an S3 Configuration section, even after you save the rule. To make changes in the S3 File Configuration:
- Click the EDIT button.
- Change the csv/tsv file, switch to another S3 bucket or make any other changes in the S3 File configuration.
- Click Load Column Details when you are done with your changes. The fields in the Columns section are automatically updated based on the columns in the new csv/tsv file.
- Click SAVE to save changes in the latest S3 File Configuration.
Important
- If you make changes to an S3 dataset task before Rule execution starts, the rule is executed successfully.
- If you make changes to the S3 File Configuration section during Rule execution, execution fails at that point. Records which were processed before the changes, remain intact. But no further records are processed after you change the csv/tsv file or S3 bucket. To learn more about how to view successfully ingested records and records which are failed to ingest, refer to the Execution History section of the Schedule and Execute Rules article.
- If you make changes to the S3 File Configuration section when the rule execution has just started or is in the execution queue, system displays an error message stating that file not found or Bucket not found, based on the changes made. The rule execution fails.
- Once you ingest data through S3 dataset, you can create an Action on the Rule to load data. If a csv/tsv file column is part of Rule Action and you wish to delete this column, from the Columns section, the system sends an error message. You must first remove the required column from the Rule Action page and then remove it from the Columns section of the S3 Dataset task.
Auto trigger a Rule with S3 Dataset
The Event Schedule Type has a scheduling mechanism called S3 File. You can use this Schedule Type to auto trigger a Rule which has S3 datasets, whenever there is a new upload in the S3 bucket. To learn more about this refer to the S3 File section of the Scheduling types article.